Welcome to Tacos Doc!

Tacos is an operating system developed in Rust for RISC-V platforms. This minimal OS incorporates Rust's design principles and is intended for educational purposes. The source code, toolchain, and documentation have been developed by our team at Peking University (refer to Acknowledgement for details). The main source code is available at https://github.com/PKU-OS/Tacos.
The code structure is designed to be modular, which means that some components of the OS can be enabled by including the corresponding source code directory for compilation. Under the src directory, some folders (e.g., sbi) are required for running the OS, while others (e.g., userproc) are only used incrementally for each lab.
This documentation contains a detailed walkthrough of how Tacos is written from scratch. We will start from an empty folder. The basic code structure for bare-metal execution is implemented in the HelloWorld section. Then, in the Memory section, we set up the kernel address space and manage the physical memory, including a global memory allocator. The code written in the above two sections is required for running the OS and will stay unchanged throughout the whole lab.
Projects
In the Thread section, we implement preemptive kernel threading. This includes the thread data structure, a simple kernel thread scheduler, and synchronization primitives. We will be able to perform concurrent programming after this section. One lab is associated with this section:
- Scheduling. We will implement an advanced scheduler that supports priority scheudling and priority donation. We will get you familiar with it by first implementing thread sleeping.
In the FileSystem section, we implement a naïve file system. We will use it to manage files and load executables from disk devices. There will be no lab associated with this section.
In the UserProgram section, we implement user-level programs. This is achieved by setting up proper execution privileges and virtual memory pages. Two labs are associated with this section:
-
Syscalls. We will implement various system calls for the user program, including process control calls (e.g.,
waitandexit) and file system operations (e.g.,readandwrite). -
Virtual Memory. We will implement virtual page swapping, and memory map system call for user programs.
Acknowledgement
Tacos is inspired by Pintos from Stanford, which was again inspired by Nachos from UC Berkeley.
Install toolchain
We provide several ways to setup the develop enviroment.
- Option A: If you're using vscode on a desktop platform, the simplest and the recommended way to setup is to use
Docker Desktopand theDev Containerplugin in vscode. - Option B: If you prefer other editors, you are encouraged to use build or use the pre-built docker image.
- Option C: Installing everything is also supported.
Before you install the toolchain, please ensure that your device have enough space (>= 5G is enough), and a good network connection.
Option A: Use pre-built Docker image and dev container (recommended)
Download docker
There are 2 ways to install docker:
- On normal desktop platform, the easiest way is to install the Docker Desktop.
- You could also install docker on linux machines follow the instructions on this page.
Start the docker desktop, or docker, after it is installed. You could use following commands to ensure it is successfully installed:
> docker --version
Docker version 20.10.17, build 100c701
Clone the skeleton code
The next step is to clone the Tacos repository:
cd /somewhere/you/like
git clone https://github.com/PKU-OS/Tacos.git
cd Tacos
Run ls under the Tacos root folder, you will see following output:
user@your_host> ls
Cargo.lock Cargo.toml Dockerfile README.md build fw_jump.bin makefile mkfs.c src target test tool user
Setup dev container
Open this folder (the project root folder) in vscode, and then run the Dev Containers: Open Folder in Container... command from the Command Palette (F1) or quick actions Status bar item, and select this folder. This step may take a while, because we are pulling a ~3G image from dockerhub.
This website displays the potential outputs that VSCode might produce during this process, feel free to use it to verify your setting.
Run Tacos
After entered the dev container, open a shell and use following command to build Tacos's disk image:
make
make builds disk.img under build/ directory, which will be used as the hard disk of Tacos. Then, you are able to run Tacos with:
cargo run
cargo run will build the kernel, and then use qemu emulator to run it. This is done by setting runner in .cargo/config.toml.
If everything goes fine, you will see following outputs:
root@8dc8de33b91a:/workspaces/Tacos# cargo run
Blocking waiting for file lock on build directory
Compiling tacos v0.1.0 (/workspaces/Tacos)
Finished dev [unoptimized + debuginfo] target(s) in 6.44s
Running `qemu-system-riscv64 -machine virt -display none -bios fw_jump.bin -global virtio-mmio.force-legacy=false --blockdev driver=file,node-name=disk,filename=build/disk.img -snapshot -device virtio-blk-device,drive=disk,bus=virtio-mmio-bus.0 -kernel target/riscv64gc-unknown-none-elf/debug/tacos`
OpenSBI v1.4-15-g9c8b18e
____ _____ ____ _____
/ __ \ / ____| _ \_ _|
| | | |_ __ ___ _ __ | (___ | |_) || |
| | | | '_ \ / _ \ '_ \ \___ \| _ < | |
| |__| | |_) | __/ | | |____) | |_) || |_
\____/| .__/ \___|_| |_|_____/|____/_____|
| |
|_|
Platform Name : riscv-virtio,qemu
Platform Features : medeleg
Platform HART Count : 1
Platform IPI Device : aclint-mswi
... (sbi outputs)
[41 ms] Hello, World!
[105 ms] Goodbye, World!
Congratulations! You have successfully setup Tacos, and are prepared for the labs! Hope you will enjoy it!
Option B: User pre-built Docker image, or manually build the image
If you don't want to use Dev Contianer, but want to use the docker image, you still need to follow the instructions in Option A to download docker and clone the code. Then you could either build the image manually or use the pre-built one.
- To manually build the image,
cdto the project root folder, and then run following command to build an image:
docker build . -t tacos
This may take a few minutes. If the build goes fine, you will see following output:
user@your_host> docker build -t tacos .
[+] Building ...s (16/16)
... (build output)
=> => exporting layers
=> => writing image
=> => naming to docker.io/library/tacos
And then start a container with following commands:
docker run --rm --name <container name> --mount type=bind,source=</absolute/path/to/this/folder/on/your/machine>,target=/workspaces/Tacos -it tacos bash
cd /workspaces/Tacos
Important
- Do not just copy and paste the command below! At least you need to replace the absolute path to your Tacos directory and the container name in the command!
- If you choose this way to setup the enviroment, you will use this command throughout this semester. It is tedious to remember it and type it again and again. You can choose the way you like to avoid this. e.g. You can use the alias Linux utility to save this command as tacos-up for example.
If you see following output, you are already inside the container:
user@your_host> docker run --rm --name <container name> --mount type=bind,source=</absolute/path/to/this/folder/on/your/machine>,target=/workspaces/Tacos -it tacos bash
root@0349a612bcf8:~# cd /workspaces/Tacos
root@0349a612bcf8:/workspaces/Tacos# ls
Cargo.lock Cargo.toml Dockerfile README.md build fw_jump.bin makefile mkfs.c src target test tool user
Then you are free to follow the running instructions in Option A.
- To use the pre-built version, run following commands:
docker pull crimmypeng/tacos:rust-1.92v3
This may take a few minutes. If the download goes fine, you will see following output:
user@your_host> docker pull crimmypeng/tacos:rust-1.92v3
rust-1.92v3: Pulling from crimmypeng/tacos
some_hash_value: Pull complete
...
some_hash_value: Pull complete
Digest: sha256:...
Status: Downloaded newer image for crimmypeng/tacos:rust-1.92v3
docker.io/crimmypeng/tacos:rust-1.92v3
And then start a container with following commands:
docker run --rm --name <container name> --mount type=bind,source=</absolute/path/to/this/folder/on/your/machine>,target=/workspaces/Tacos -it crimmypeng/tacos:rust-1.92v3 bash
cd /workspaces/Tacos
If you see following output, you are already inside the container:
user@your_host> docker run --rm --name <container name> --mount type=bind,source=</absolute/path/to/this/folder/on/your/machine>,target=/workspaces/Tacos -it tacos bash
root@0349a612bcf8:~# cd /workspaces/Tacos
root@0349a612bcf8:/workspaces/Tacos# ls
Cargo.lock Cargo.toml Dockerfile README.md build fw_jump.bin makefile mkfs.c src target test tool user
Remember that you need to replace the absolute path to your Tacos directory and the container name in the command. If you choose this way to setup, you will use above command throughout this semester.
Then you are free to follow the running instructions in Option A.
Option C: Install from scratch
The first thing would always be to install Rust and the build tool Cargo. Since our OS will run on a RISC-V machine, we also need to add cross-compiling targets to rustc:
rustup target add riscv64gc-unknown-none-elf
Our OS runs on machine simulator - QEMU. Follow the referenced link to install it.
Hello, world!
Now we are ready to write an OS from scratch! Let's initialize an empty project:
$ git init -b main
$ cargo init tacos
This section will go through the very basic structure of the whole system - how to compile, link, load, and execute stuff we write. Debugging techniques will be discussed too. Some code in this section is not actually part of the codebase - necessary simplifications are made to keep this section self-contained.
First instruction
The goal of this section is to execute one instruction on QEMU. With the support of modern OS, we can readily compile an executable and ask the OS to load it - but now no one is there to help us. We will need to craft a binary file and feed it to QEMU.
[no_std]-ifying
By default, rustc compiles with a lot of extra OS-dependent things, and giving us a binary that can only be understood by the current platform. These stuff are called std - Rust Standard Library, and we can't use any of them on a bare metal system. Also, we need to have full control of the binary we are generating, including where should the entry point be. Fortunately, rustc permits this with the #![no_std] and #![no_main] global attributes, along with a empty panic handler:
File: src/main.rs
#![allow(unused)] #![no_std] #![no_main] fn main() { #[panic_handler] fn panic(_: &core::panic::PanicInfo) -> ! { loop {} } }
That actually compiles, provided that we have the right target:
$ cargo build --target riscv64gc-unknown-none-elf
Compiling tacos v0.1.0 (/path/to/tacos)
Finished dev [unoptimized + debuginfo] target(s) in 0.20s
At this point, we have generated an object file with empty content. Now let's try to add our first instruction by injecting some assembly into the source file:
File: src/main.rs
#![allow(unused)] fn main() { core::arch::global_asm! {r#" .section .text globl _start _start: addi x0, x1, 42 "#} }
Linking by hand
We have no idea where the .text section is located. If an OS exists, it could read the output object file and determine the _entry point. But on a bare metal system, we have to manually design the layout of the whole codebase such that the hardware can just treat it as an unstructured binary and go ahead executing whatever is on the upfront.
Linker script is a standard way to customize binary layout. We can specify the address of each section we created in the source files. Let's put this instruction to where QEMU is able to find:
File: src/linker.ld
OUTPUT_ARCH(riscv)
SECTIONS
{
. = 0x0000000080200000;
.text : { *(.text) }
/DISCARD/ : { *(.eh_frame) }
}
Just to clearify, the section and segment .text are arbitrarily named - call them whever you want as long as the names are consistent in the source file and linker script.
QEMU's physical address starts at 0x80000000, and at that address, there's a small code snippet that comes with it - Supervisor Binary Interface (SBI). It is responsible for setting up the machine and providing basic services, and we will back it up later. In the linker script, the load address 0x80200000 works because we know the size of SBI will not exceed it.
Now we can compile our instruction with the linker script
RUSTFLAGS=-Clink-arg=-Tsrc/linker.ld cargo build --target riscv64gc-unknown-none-elf
and ask QEMU to load and simulate the generated target on a virtual machine
qemu-system-riscv64 -nographic -machine virt -kernel target/riscv64gc-unknown-none-elf/debug/tacos
If nothing went wrong, it will stuck after printing some pretty welcome message:
OpenSBI v1.2
____ _____ ____ _____
/ __ \ / ____| _ \_ _|
| | | |_ __ ___ _ __ | (___ | |_) || |
| | | | '_ \ / _ \ '_ \ \___ \| _ < | |
| |__| | |_) | __/ | | |____) | |_) || |_
\____/| .__/ \___|_| |_|_____/|____/_____|
| |
|_|
Platform Name : riscv-virtio,qemu
Platform Features : medeleg
Platform HART Count : 1
Platform IPI Device : aclint-mswi
Platform Timer Device : aclint-mtimer @ 10000000Hz
Platform Console Device : uart8250
Platform HSM Device : ---
Platform PMU Device : ---
Platform Reboot Device : sifive_test
Platform Shutdown Device : sifive_test
Firmware Base : 0x80000000
Firmware Size : 212 KB
Runtime SBI Version : 1.0
Domain0 Name : root
Domain0 Boot HART : 0
Domain0 HARTs : 0*
Domain0 Region00 : 0x0000000002000000-0x000000000200ffff (I)
Domain0 Region01 : 0x0000000080000000-0x000000008003ffff ()
Domain0 Region02 : 0x0000000000000000-0xffffffffffffffff (R,W,X)
Domain0 Next Address : 0xfffffffffffff000
Domain0 Next Arg1 : 0x0000000087e00000
Domain0 Next Mode : S-mode
Domain0 SysReset : yes
Boot HART ID : 0
Boot HART Domain : root
Boot HART Priv Version : v1.12
Boot HART Base ISA : rv64imafdch
Boot HART ISA Extensions : time,sstc
Boot HART PMP Count : 16
Boot HART PMP Granularity : 4
Boot HART PMP Address Bits: 54
Boot HART MHPM Count : 16
Boot HART MIDELEG : 0x0000000000001666
Boot HART MEDELEG : 0x0000000000f0b509
We don't want to type this everytime, so let's put it down and we can go with cargo run afterwards:
File: .cargo/config.toml
[build]
target = "riscv64gc-unknown-none-elf"
[target.riscv64gc-unknown-none-elf]
rustflags = ["-Clink-arg=-Tsrc/linker.ld"]
runner = "qemu-system-riscv64 -nographic -machine virt -kernel"
Why it "halts"?
It's not actually halting. Since we've only loaded one instruction, the rest of the memory is uninitialized - and very likely to contain invalid instructions. Even if we are lucky and not encountering invalid instructions, the memory is small and the program counter will soon go out of the boundary. In whichever case, we are in trouble and SBI will take over control and try resetting everything - and the above loop goes over and over again.
First function
No one would ever want to write an OS in assembly. This section aims to transfer the control flow to Rust.
From assembly to Rust
Recall that in the previous section, we've compiled and linked the instruction addi x0, x1, 42 to the correct place. Following this line, let's jump:
File: src/main.rs
core::arch::global_asm! {r#" .section .text .globl _start _start: li sp, 0x80400000 j main "#} #[no_mangle] extern "C" fn main() -> ! { loop {} }
An empty main is created and the dummy addi is replaced with j. A few other things happened here:
-
The
extern "C"is part of the Foreign Function Interface (FFI) - a set of compiler arguments to make foreign function calls are compatible. Since we are transfering from assembly, which is not part of the Rust standard,rustcis free to changing the calling convention in the future. This attribute ensuresj main, the way function get called inC, always works. -
The
#[no_mangle]attribute asks the compiler not to mess up the namemain. If not,rustcwill probably rename it to something like__ZNtacos4main17h704e3c653e7bf0d3E- not sweet for someone who need to directly reference the symbol in assembly. -
The stack pointer is initialized by some memory address. If nothing is loaded to
sp, a page fault will be triggered oncespis accessed to save the call stack. Once again,0x80400000is an arbitrary address which will not overlap with anything useful, for now.
More sections
The above main is probably too naïve. Let's try coding with some Rust-y magic:
File: src/main.rs
static ZERO: [u8; 100] = [0; 100]; static DATA: u32 = 0xDEADBEEF; #[no_mangle] extern "C" fn main() -> ! { assert!(ZERO[42] == 0); assert!(DATA != 0); for i in Fib(1, 0).take(10000) { drop(i) } loop {} } struct Fib(usize, usize); impl Iterator for Fib { type Item = usize; fn next(&mut self) -> Option<usize> { let value = self.0 + self.1; self.1 = self.0; self.0 = value; Some(value) } }
Now, there are multiple segments in .text, and we need to make sure the assembly snippet is executed first. We create a separate section for it and link that section first. Apart from this, we want to reserve some space for the kernel stack.
File: src/main.rs
#![allow(unused)] fn main() { core::arch::global_asm! {r#" .section .text.entry globl _start _start: la sp, _stack j main .section .data .globl _stack .align 4 .zero 4096 * 8 _stack: "#} }
The size of the stack is set to 32kb - still arbitrary but quite enough for our current kernel. The linker script in the previous section probably won't work now, since there're data segments and we need to include them:
File: src/linker.ld
SECTIONS
{
. = 0x0000000080200000;
.text : {
*(.text.entry)
*(.text*)
}
.data : { *(.*data*) }
.bss : {
sbss = .;
*(.*bss*)
ebss = .;
}
/DISCARD/ : { *(.eh_frame) }
}
Don't forget B.S.S.
As you've probably noticed, we left some symbols in .bss. It's always good to keep in mind that no one is doing anything for us, including clearing up the .bss segment. Forgetting to do so probably works fine on a simulator - but will definitely cause trouble on real machines.
File: src/mem.rs
#![allow(unused)] fn main() { pub fn clear_bss() { extern "C" { fn sbss(); fn ebss(); } unsafe { core::ptr::write_bytes(sbss as *mut u8, 0, ebss as usize - sbss as usize) }; } }
SBI support
Up to now, we only have access to the CPU itself (and haven't managed to print Hello, World!). In this section, we will talk about how SBI helps us to do basic interactions with the platform.
About SBI
Supervisor Binary Interface (SBI) provides us with a limited but out-of-box interface for interacting with the platform. As you all know, RISC-V has several privileged execution levels, and our OS runs in the middle: Supervisor (S)-mode. Firmware, on the other hand, runs on the Machine (M)-mode, and is responsible for backing up all platform-specific setups. SBI is the protocol that firmware uses to serve us, similar to syscall but at a lower abstraction level.
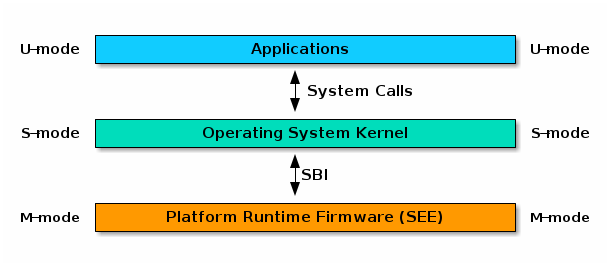
We will not cover the tedious calling specification here, and provide a macro that just does the job:
File: src/macros.rs
#![allow(unused)] fn main() { macro_rules! sbi_call { // v0.1 ( $eid: expr; $($args: expr),* ) => { sbi_call!($eid, 0; $($args),*).0 }; // v0.2 ( $eid: expr, $fid: expr; $($arg0: expr $(, $arg1: expr )?)? ) => { { let (err, ret): (usize, usize); unsafe { core::arch::asm!("ecall", in("a7") $eid, lateout("a0") err, in("a6") $fid, lateout("a1") ret, $(in("a0") $arg0, $(in("a1") $arg1)?)? ); } (err, ret) } }; } }
Built on that, now the machine can power off gracefully. (Remember the simulator halts everytime? Now it terminates itself!)
File: src/sbi.rs
#![allow(unused)] fn main() { pub fn shutdown() -> ! { sbi_call!(0x08;); unreachable!() } }
Kernel output
Time to write our own output using the above SBI calls! Our own implementation of the Write trait will be used by core::fmt to output formatted string:
File: src/sbi/console.rs
#![allow(unused)] fn main() { pub struct Kout; impl core::fmt::Write for Kout { fn write_str(&mut self, string: &str) -> core::fmt::Result { for char in string.chars() { sbi_call!(0x01; char as usize); } Ok(()) } } }
File: src/macros.rs
#![allow(unused)] fn main() { macro_rules! kprint { ($($arg:tt)*) => {{ use core::fmt::Write; drop(write!($crate::sbi::Kout, $($arg)*)); }}; } macro_rules! kprintln { () => { kprint("\n") }; ($($arg:tt)*) => { kprint!($($arg)*); kprint!("\n"); }; } }
Putting them all together, let's say hello to the world and then gracefully shut down the machine:
File: src/main.rs
#[macro_use] mod macros; mod mem; mod sbi; #[no_mangle] fn main() -> ! { kprintln!("Hello, World!"); sbi::shutdown() }
Memory
In this section, we will talk about one of the most important thing that our kernel will manage - the memory. Spcifically, we will first place kernel in the right address, and implement both page allocator and heap allocator which almost all kernel functionalities rely on.
Kernel layout
At the end of the Hello, World! section, our kernel is a compact binary located right at the beginning of physical memory. In order to provide isolation from user programs later, we place the kernel code to somewhere else. One can of course keep kernel here and use another virtual page, plus some tranpoline tricks, to achieve this. But we've chosen to move kernel because of simplicity and our design choice.
Below shows typical memory layout for a running kernel:
PHYSICAL MEMORY VIRTUAL MEMORY VIRTUAL MEMORY
(KERNEL) (USER PROGRAM)
┌────────────────────────┐ ┌────────────────────────┐ 0xFFFFFFFFFFFFFFFF
· · · ·
├────────────────────────┤ ├────────────────────────┤
│ │ │ │
│ KERNEL │ │ KERNEL │
│ │ │ │
├────────────────────────┤ ├────────────────────────┤ 0xFFFFFFC080200000
· · · ·
┌────────────────────────┐ · · │ │
│ │ · · │ │
│ PAGE │ · · │ │
│ │ · · │ USER PROGRAM │
├────────────────────────┤ · · │ │
│ │ · · │ │
│ KERNEL │ · · │ │
│ │ · · │ │
├────────────────────────┤ ├────────────────────────┤ ├────────────────────────┤ 0x80200000
│ OPEN SBI │ │ OPEN SBI │ · ·
├────────────────────────┤ ├────────────────────────┤ · · 0x80000000
· · · · · ·
├────────────────────────┤ ├────────────────────────┤ · ·
│ MMIO │ │ MMIO │ · ·
├────────────────────────┤ ├────────────────────────┤ · · 0x10001000
· · · · · ·
└────────────────────────┘ └────────────────────────┘ └────────────────────────┘ 0x0
The kernel runs at the higher address space 0xFFFFFFC080200000, shifting from its physical address 0x80200000 by 0xFFFFFFC000000000. Below we define some utilities:
File: src/mem.rs
#![allow(unused)] fn main() { pub const BASE_LMA: usize = 0x0000000080000000; pub const BASE_VMA: usize = 0xFFFFFFC080000000; pub const OFFSET: usize = BASE_VMA - BASE_LMA; /// Is `va` a kernel virtual address? pub fn is_vaddr<T>(va: *mut T) -> bool { va as usize >= BASE_VMA } /// From virtual to physical address. pub fn vtop<T>(va: *mut T) -> usize { assert!(is_vaddr(va as *mut T)); va as usize - OFFSET } /// From physical to virtual address. pub fn ptov<T>(pa: usize) -> *mut T { assert!(!is_vaddr(pa as *mut T)); (pa + OFFSET) as *mut T } }
Link the kernel
In the previous linker script, anything is linked at its physical address - the linker assumes the code runs at where it was compiled. But since we are running the whole kernel at the higher address space, the pc is shifted from where it was compiled - when weird things could happen. To resolve this, we use the AT keyword to specify load address that is different from virtual address. In this linker script, every virtual address is shifted by 0xFFFFFFC000000000, but shifted back for load address:
File: src/linker.ld
BASE_LMA = 0x0000000080000000;
BASE_VMA = 0xFFFFFFC080000000;
OFFSET = BASE_VMA - BASE_LMA;
SECTIONS
{
. = BASE_VMA;
. += 0x200000;
.text : AT(. - OFFSET) {
*(.text.entry)
*(.text*)
}
. = ALIGN(4K);
etext = .;
.data : AT(. - OFFSET) { *(.*data*) }
.bss : AT(. - OFFSET) {
sbss = .;
*(.*bss*)
ebss = .;
}
. = ALIGN(4K);
ekernel = .;
/DISCARD/ : { *(.eh_frame) }
}
Move the kernel
The kernel is moved by creating a kernel pagetable, which has
-
An identity mapping for the whole kernel image at its physical address (starting from
0x80000000). This is done by registering a 1GB large page to the third page table entry. -
Another large page that maps
0xFFFFFFC080000000to0x80000000similiarily.
File: src/main.rs
#![allow(unused)] fn main() { core::arch::global_asm! {r#" .section .data .globl _pgtable .align 12 _pgtable: .zero 4096 .section .text.entry .globl _start _start: la t0, _pgtable addi t1, t0, 1024 li t2, 0x2000002F # maps 0x80000000+1GB sd t2, 16-1024(t1) # to 0x80000000+1GB, and sd t2, 16+1024(t1) # to 0xFFFFFFC080000000+1GB srli t0, t0, 12 # set the PPN field of satp li t1, 0x8 << 60 or t0, t0, t1 # set MODE=8 to use SV39 sfence.vma zero, zero csrw satp, t0 # enable page table sfence.vma zero, zero la sp, _stack ld t0, _main jr t0 "#} }
Note that we are jumping a little bit differently: instead of directly j main, we load from the symbol _main and jr to it. The symbol _main stores the address of main - why are we doing this? The answer is in the RISC-V ISA itself. The j instruction, which is a pseudo-instruction of jal, works by relative addressing. If we just call j main, the PC will still be in lower address space. Therefore we have to store the (absolute) address of the symbol main into memory, and then jump there:
File: src/main.rs
#![allow(unused)] fn main() { core::arch::global_asm! {r#" .section .data .globl _main _main: .dword main "#} }
Page allocator
Our kernel is currently "static": all data structure's lifetime is determined at compile time. While the standard library allows rustc to compile code with dynamic memory allocation, we now need to implement this interface ourselves. But we haven't gone that far yet: we need to first define an interface that can manage physical pages - 4kb segments in RAM.
File: src/mem/page.rs
#![allow(unused)] fn main() { pub const PGBITS: usize = 12; pub const PGSIZE: usize = 1 << PGBITS; pub const PGMASK: usize = PGSIZE - 1; /// Page number of virtual address `va`. pub fn number<T>(va: *const T) -> usize { va as usize >> PGBITS } /// Page offset of virtual address `va`. pub fn offset<T>(va: *const T) -> usize { va as usize & PGMASK } /// Base address of the next page. pub fn round_up<T>(va: *const T) -> usize { (va as usize + PGSIZE - 1) & !PGMASK } /// Base address of current page. pub fn round_down<T>(va: *const T) -> usize { va as usize & !PGMASK } }
In-memory lists
We need single-linked lists to manage page allocation, and as usual, we have to implement them on our own.
For someone who is new to Rust, this blog post Learn Rust With Entirely Too Many Linked Lists is among the "must read" articles that explain the Rust memory system. It talks about how (hard) linked lists - probably the most basic data structure - can be implemented in Rust. But here we need something different: examples in that article rely on existing memory allocators. In our case, a large RAM segment is all we have. We need to directly read and write unstructured memory to build our lists.
File: src/mem/list.rs
#![allow(unused)] fn main() { #[derive(Clone, Copy)] pub struct List { pub head: *mut usize, } }
The list is simply a raw pointer to the head node. Each node, not explicitly defined, is a usize in memory. Its content, interpreted as *mut usize, is also a memory address pointing to the next node. Now we implement how a memory address can be appended to and removed from the list:
File: src/mem/list.rs
#![allow(unused)] fn main() { impl List { pub const fn new() -> Self { List { head: core::ptr::null_mut(), } } pub unsafe fn push(&mut self, item: *mut usize) { *item = self.head as usize; self.head = item; } pub unsafe fn pop(&mut self) -> Option<*mut usize> { match self.head.is_null() { true => None, false => { let item = self.head; self.head = *item as *mut usize; Some(item) } } } pub fn iter_mut<'a>(&'a mut self) -> IterMut<'a> { IterMut { list: core::marker::PhantomData, node: Node { prev: core::ptr::addr_of_mut!(self.head) as *mut usize, curr: self.head, }, } } } }
To help us traverse the list in an easy way, we also define a mutable iterator struct IterMut which remembers the previous node. The implementation is standard and the code is omitted for simplicity.
Buddy allocation
We use the buddy memory allocation scheme to manage free and used pages.
File: src/mem/page.rs
#![allow(unused)] fn main() { use crate::mem::list::List; const MAX_ORDER: usize = 10; /// Buddy memory allocator. pub struct Allocator([List; MAX_ORDER + 1]); impl Allocator { pub const fn new() -> Self { Self([List::new(); MAX_ORDER + 1]) } /// Register the memory segmant from `start` to `end` into the free list. pub unsafe fn insert_range(&mut self, start: *mut u8, end: *mut u8) { let (mut start, end) = (round_up(start), round_down(end)); while start < end { let level = (end - start).next_power_of_two().trailing_zeros(); let order = MAX_ORDER.min(level as usize - PGBITS); self.0[order].push(start as *mut usize); start += PGSIZE << order; } } /// Allocate `n` pages and return virtual address. pub unsafe fn alloc(&mut self, n: usize) -> *mut u8 { let order = n.next_power_of_two().trailing_zeros() as usize; for i in order..=MAX_ORDER { // Find a block of great order if !self.0[i].head.is_null() { for j in (order..i).rev() { // Split the block into two sub-blocks if let Some(full) = self.0[j + 1].pop() { let half = full as usize + (PGSIZE << j); self.0[j].push(half as *mut usize); self.0[j].push(full); } } return self.0[order].pop().unwrap().cast(); } } panic!("memory exhausted"); } /// Free `n` previously allocated physical pages. pub unsafe fn dealloc(&mut self, ptr: *mut u8, n: usize) { let order = n.next_power_of_two().trailing_zeros() as usize; // Fill it with trash to detect use-after-free core::ptr::write_bytes(ptr, 0x1C, n * PGSIZE); self.0[order].push(ptr.cast()); let mut curr_ptr = ptr as usize; for i in order..=MAX_ORDER { let buddy = curr_ptr ^ (1 << i); // Try to find and merge blocks if let Some(block) = self.0[i].iter_mut().find(|blk| blk.curr as usize == buddy) { block.remove(); // Merge two blocks into a larger one self.0[i + 1].push(curr_ptr as *mut _); self.0[i].pop(); // Merged block of order + 1 curr_ptr = curr_ptr.min(buddy); } else { break; } } } } }
Heap memory
In the previous section, we implemented a page allocator that can manage physical pages. Now we are ready to implement fine-grained dynamic allocation, and make full use of the Rust memory system.
Arena allocation
We use arena memory allocation for fine-grained memory management. We will not cover the details for now. In the end, we have defined a struct that does similar job as the page allocator, except that the allocation unit is byte instead of physical page:
File: src/mem/heap.rs
#![allow(unused)] fn main() { pub struct Allocator { fields omitted... } impl Allocator { pub const fn new() -> Self; /// Allocates a memory block that is in align with the layout. pub unsafe fn alloc(&mut self, layout: Layout) -> *mut u8; /// Deallocates a memory block pub unsafe fn dealloc(&mut self, ptr: *mut u8, layout: Layout); } }
Rust global allocator
We want to make use of Rust built-in data structures: Box, Vec, etc. This is made possible by implementing the GlobalAllocator trait, provided by the standard library. This is an interface that std will make use of to implement downstream data structures as mentioned before. One could of course go implement them from scratch, but why not go with an easier way:
File: src/mem.rs
#![allow(unused)] fn main() { pub static HEAP: heap::Allocator = heap::Allocator::new(); pub struct Malloc; unsafe impl GlobalAlloc for Malloc { unsafe fn alloc(&self, layout: Layout) -> *mut u8 { HEAP.alloc(layout) } unsafe fn dealloc(&self, ptr: *mut u8, layout: Layout) { HEAP.dealloc(ptr, layout) } } #[global_allocator] static MALLOC: Malloc = Malloc; }
Kernel thread
This section will cover kernel threads. These threads directly runs in the kernel space, and we will build schedulers to achieve concurrency. Along the way, we will introduce different types of synchronization to our kernel, which brings safety to concurrent execution.
Introduction
In this section, we will implement kernel thread in Tacos. Before delving into the details, let's take a look at the abstractions we're going to build. Thread API in Rust is neater than pthread, and we will support similar interfaces in Tacos. Understand Send and Sync traits will avoid a large proportion of concurrent bugs. Kernel thread and user thread are similar in many ways, so we will review the property of user threads and compare kernel threads and user threads. Finally, we will compare kernel threads and user threads as a conclusion to this section.
Thread API in Rust
Now let's have a review of the how Rust models thread and relavent concepts, because we will implement similar APIs in the kernel(in crate::thread).
In Rust std, the thread creation function, thread::spawn, accepts a closure as it's main function. In contrast to POSIX, argument passing is made easy by using the move keyword to capture the ownership of arguments that are carried along with the thread itself. The example shows a simple example of summing a vector in another thread.
use std::thread; fn main() { let v: Vec<i32> = vec![1, 2, 3]; let handle = thread::spawn(move || { v.into_iter().sum() }); let sum: i32 = handle.join().unwrap(); println!("{}", sum); }
The Send and Sync traits
The Send and Sync traits, together with the ownerhip system, are extensively used in Rust to eliminate data race in concurrent programming. This document discusses these traits in depth, and here we explains some essential concepts that will be relavent to our implementation:
-
Synctrait represents the ability of be referenced by multiple threads; therefore, a global variable in Rust must beSync. Many types that we encounter when writing general purpose Rust code areSync. However, data structures that contain raw pointers, no matter if they areconstormut, are generally notSync. Raw pointers have no ownership, and lack exclusive access guarentee to the underlying data. Therefore, in the context of concurrent programming, most of the data structures we have defined so far can not be directly put in the global scope. -
Sendtrait is in some sense a weaker constraint, representing the safetyness of moving a type to another thread. For example, theCellfamily is notSyncsince it has no synchronization, but it isSend. Other types, such asRc<T>, are neitherSyncnorSend.
A type T is Sync if and only if &T is Send.
Synchronization in Rust
Two primary methods exist for synchronization are message passing and shared memory. In Rust std, channels are designed for message passing, while Mutexs are designed for accessing shared memory. Following example shows the usage of Mutex and channel.
use std::sync::{Mutex, mpsc};
use std::thread;
static COUNTER: Mutex<i32> = Mutex::new(0);
fn main() {
let (sx, rx) = mpsc::channel();
sx.send(&COUNTER).unwrap();
let handle = thread::spawn(move || {
let counter = rx.recv().unwrap();
for _ in 0..10 {
let mut num = counter.lock().unwrap();
*num += 1;
}
});
for _ in 0..10 {
let mut num = COUNTER.lock().unwrap();
*num += 1;
}
handle.join().unwrap();
println!("num: {}", COUNTER.lock().unwrap());
}
The type of the global variable COUNTER is Mutex<i32>, which implements the Sync trait. A global variable can be referenced by multiple threads, therefore we need Sync trait to avoid data races.
We use channel to pass a reference of COUNTER to another thread (remember that &Mutex<i32> is Send, allowing us to safely send it to another thread).
We use Mutex to ensure exclusive access. To access the data inside the mutex, we use the lock method to acquire the lock, which is a part of the Mutex struct. This call will block the current thread so it can’t do any work until it’s our turn to have the lock. The call to the lock method returns a smart pointer called MutexGuard, which implements Deref to point at our inner data, and implements Drop to release the lock automatically when a MutexGuard goes out of scope.
User Threads v.s. kernel space
In this document, user threads refers to threads inside a user program. User threads are:
- in a same program, thus share the same address space
- running different tasks concurrently, thus each thread has an individual stack, PC, and registers
Similarly, kernel threads refers to threads inside the OS kernel. Like user threads, kernel threads are:
- in the same kernel, thus share the kernel address space
- running different tasks concurrently, thus each kernel thread has an individual stack, PC, and registers
Multi-threaded programming in user spaces uses APIs provided by the OS, such as pthreads(You should be familar with it! You may have learned it in ICS. You should consider drop this course if you haven't learned it...). By using those APIs, the OS maintains the address space, stack, PC and registers for user. However, as we are implementing an OS, we have to build it from scratch and maintain those states manually. In the following parts of this chapter, we will build it step by step.
The table below compares the standard thread in modern OS and the kernel thread introduced in the section:
| Thread in modern OS | Kernel thread | |
|---|---|---|
| Executes in | user mode | privileged mode |
| Address space | user address space | kernel address space |
| APIs | pthread, etc. | crate::thread |
| States | managed by OS | managed by yourself |
Currently Tacos does not support user threads. In this document, for the sake of brevity, when we use the term thread, it refers to to a kernel thread.
Support different tasks: Thread context
Now we are going to build data structures to support executing a specific task in a kernel thread! Tacos wasn't built in a day, as well as its thread module. Let's begin with the simplest scenario: support only the creation of a thread, in another word, we are going to implement following function:
/// Create a new thread
pub fn spawn<F>(name: &'static str, f: F) -> Arc<Thread>
where
F: FnOnce() + Send + 'static,
{
...
}
Running a thread has not yet been supported! We will discuss running a thread later.
Exercise
What is the meaning of the clause
where F: FnOnce() + Send + 'static? Why do we needFto beSend? What is the meaning of'static?
The Thread struct and its member
As mentioned in the previous part, the context of a kernel thread contains address spaces, stack, PC, and registers. To create a kernel thread, we must build a set of context. Address spaces are decided by the pagetable. Fortunately, kernel threads share the same address space, which means we do not need to create a new one. But for other parts of the context, we have to build datastructures to maintain them. We will discuss Thread struct first.
File: src/thread/imp.rs
#[repr(C)]
pub struct Thread {
tid: isize,
name: &'static str,
stack: usize,
context: Mutex<Context>,
...
}
impl Thread {
pub fn new(
name: &'static str,
stack: usize,
entry: usize,
...
) -> Self {
/// The next thread's id
static TID: AtomicIsize = AtomicIsize::new(0);
Thread {
tid: TID.fetch_add(1, SeqCst),
name,
stack,
context: Mutex::new(Context::new(stack, entry)),
...
}
}
pub fn context(&self) -> *mut Context {
(&mut *self.context.lock()) as *mut _
}
...
}
Thread is a thread control block(TCB). Above code shows the definition of the Thread struct(We omit some fields for brevity. Those fields will be discussed in the following parts). Each Thread has a tid, which is used to identify a thread. TID is an incrementing static variable, we use it to assign distinct tids for threads. name is set to help the debug process. The stack and context is used to record the context of the Thread. We will discuss them immediately.
Maintain stack for kernel thread
To execute a task, a thread may allocate variables on stack, or call other functions. Either operation needs a runtime stack. As you may have remembered, in the Hello World section we manually allocated the stack for the first function in src/main.rs. After page allocator is ready, we are free to allocate dynamic memory and use it as a stack. In Tacos, we alloc 16KB for a thread stack(luxury!). Following code shows the allocation of stack:
File: src/thread.rs
pub fn spawn<F>(name: &'static str, f: F) -> Arc<Thread>
where
F: FnOnce() + Send + 'static,
{
...
let stack = kalloc(STACK_SIZE, STACK_ALIGN) as usize;
...
// Return created thread:
Arc::new(Thread::new(name, stack, ...))
}
We record that stack in Thread and use kfree to deallocate the stack as the thread terminates.
Maintain registers for kernel thread
Each thread holds a set of general purpose registers. In riscv, they are x0~x31 (checkout this link for more details). As we create a new thread in Tacos, we should set the initial value of x0~x31. When we are switching to another thread (we will cover the details in the next section), those values should also be saved properly. We use Context struct to represent recorded registers:
File: src/thread/imp.rs
/// Records a thread's running status when it switches to another thread,
/// and when switching back, restore its status from the context.
#[repr(C)]
#[derive(Debug)]
pub struct Context {
/// return address
ra: usize,
/// kernel stack
sp: usize,
/// callee-saved
s: [usize; 12],
}
impl Context {
fn new(stack: usize, entry: usize) -> Self {
Self {
ra: kernel_thread_entry as usize,
// calculate the address of stack top
sp: stack + STACK_SIZE,
// s0 stores a thread's entry point. For a new thread,
// s0 will then be used as the first argument of `kernel_thread`.
s: core::array::from_fn(|i| if i == 0 { entry } else { 0 }),
}
}
}
Let's skip the kernel_thread_entry and the argument entry for a while -- and focus on the fields of Context struct. The sp stores the stack pointer, the ra stores the return address, and the s array stores the callee saved registers in riscv, named s0~s11 (In riscv, a register could be referenced by its alias. For example, sp is the alias of x2).
In the Thread struct, the type of the context field is Mutex<Context>, however the type stack, name and tid are just basic types. Why? That is because stack, name and tid is immutable after a Thread struct is constructed, they remains unchanged until it drops. But the context field is mutable, and we do need to change it when we are switching to another thread. Mutex is added to obtain innter mutability and we will implement it later (The interface is like std::Mutex). You will get a better understanding after we covered the context switching part.
You may want to ask: in the Context struct, only 1 + 1 + 12 = 14 registers are saved. What about other registers? Where should we save them? What should their initial values be set to? That is a good question! The short answer is: the initial value of any register is not important (In fact, you could pass an argument to the thread use some of the registers: for example, in Tacos we use s0 to pass a pointer), and caller saved registers are saved on the stack during context switching. We will explain the details in the next section.
Capture the closure as the main function
We have already allocated spaces for a thread's execution, now it is time to give it a task. The spawn accepts a closure, which is the main funtion of another thread, and belongs to the thread. Therefore, we must support inter-thread communication and pass the closure to another thread. Remember that kernel threads shares the same address space -- which means we could simply put the closure on the heap, and read it from another thread. Following code shows how we store it on the heap:
File: src/thread.rs
pub fn spawn<F>(name: &'static str, f: F) -> Arc<Thread>
where
F: FnOnce() + Send + 'static,
{
// `*mut dyn FnOnce()` is a fat pointer, box it again to ensure FFI-safety.
let entry: *mut Box<dyn FnOnce()> = Box::into_raw(Box::new(Box::new(function)));
let stack = kalloc(STACK_SIZE, STACK_ALIGN) as usize;
...
Arc::new(Thread::new(name, stack, entry, ...))
}
Just to remind you, the entry passed to Thread::new will be passed to the Context::new, and then recorded in the initial context. Which means, when a thread is about to start, its s0 register is an pointer to its main function, a boxed closure. (Of course we need some extra works to implement this! But please pretend that we could do this.)
In order to read the closure in another thread, we wrote two functions: kernel_thread_entry and kernel_thread:
File: src/thread/imp.rs
global_asm! {r#"
.section .text
.globl kernel_thread_entry
kernel_thread_entry:
mv a0, s0
j kernel_thread
"#}
#[no_mangle]
extern "C" fn kernel_thread(main: *mut Box<dyn FnOnce()>) -> ! {
let main = unsafe { Box::from_raw(main) };
main();
thread::exit();
}
kernel_thread_entry is a little bit tricky. It is the real entry point of spawned thread, reads the value in s0 (the pointer), and move it to a0 register (the first argument), and jump (call also works) to the kernel_thread function. The kernel_thread function reads the boxed closure and run the closure, and calls an exit function to terminate the thread.
Put it together: the thread Manager
The kernel maintains a table of active threads. When a thread is created, the thread is added to the table. When a thread exits, the thread is removed from the table. In Tacos, we use Manager struct as that table. You can think of it as a singleton.
File: src/thread/manager.rs
pub struct Manager {
/// All alive and not yet destroyed threads
all: Mutex<VecDeque<Arc<Thread>>>,
...
}
impl Manager {
/// Get the singleton.
pub fn get() -> &'static Self { ... }
pub fn resiter(&self, thread: Arc<Thread>) {
// Store it in all list.
self.all.lock().push_back(thread.clone());
...
}
}
Exercise
The type of the
allfield isMutex<...>. Why?
The spawn function should register the thread to the Manager.
File: src/thread.rs
pub fn spawn<F>(name: &'static str, f: F) -> Arc<Thread>
where
F: FnOnce() + Send + 'static,
{
// `*mut dyn FnOnce()` is a fat pointer, box it again to ensure FFI-safety.
let entry: *mut Box<dyn FnOnce()> = Box::into_raw(Box::new(Box::new(function)));
let stack = kalloc(STACK_SIZE, STACK_ALIGN) as usize;
...
let new_thread = Arc::new(Thread::new(name, stack, entry, ...));
Manager::get().register(new_thread.clone());
new_thread
}
Congratulations! Now you could create a new thread in Tacos.
Enable time sharing
Follow the instructions in the previous section, you are able to create kernel threads. In order to run them, we must support thread shceduling -- it enables a thread to yield the CPU to another one. Again, let's begin from the simplest step: support thread scheduling on a non-preemptive CPU (which means every thread will not be interrupted. It continues running until it yields explicitly by calling schedule()). Therefore, we need to support following APIs:
/// Get the current running thread
pub fn current() -> Arc<Thread> { ... }
/// Yield the control to another thread (if there's another one ready to run).
pub fn schedule() { ... }
/// Gracefully shut down the current thread, and schedule another one.
pub fn exit() -> ! { ... }
Schedule trait is designed to support the schedule process. In this part, we will also write a FIFO scheduler that implements the Schedule trait. Understand it may be helpful to your project!
States of a kernel thread
Now consider there are multiple threads inside the kernel. Those threads are in different states. At a given time, a thread can be in one of four states: Running, Ready, Blocked and Dying. Running simply means the thread is running (As the OS is running on a single-core processor, there is only one Running thread at any given time). A thread in Ready state is ready to be scheduled. Blocked threads are blocked for different reasons(e.g. IO, wait for another thread to terminate, etc. It is complex, so we are not covering it in this section). Dying is a little bit tricky, we label a thread as Dying to release its resources in the (hopefully near) future. The state transitions are illustrated in the following graph.
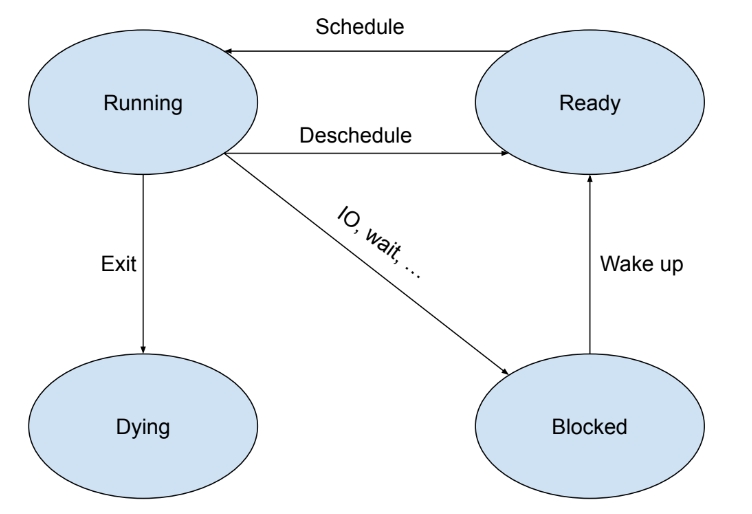
Those states can be found in:
File: src/thread/imp.rs
#![allow(unused)] fn main() { /// States of a thread's life cycle #[derive(Debug, Clone, Copy, PartialEq, Eq)] pub enum Status { /// Not running but ready to run Ready, /// Currently running Running, /// Waiting for an event to trigger Blocked, /// About to be destroyed Dying, } }
And a Thread struct contains a status field. It is also inside a Mutex beacuse it is mutable.
File: src/thread/imp.rs
#[repr(C)]
pub struct Thread {
tid: isize,
name: &'static str,
stack: usize,
status: Mutex<Status>,
context: Mutex<Context>,
...
}
impl Thread {
...
pub fn status(&self) -> Status {
*self.status.lock()
}
pub fn set_status(&self, status: Status) {
*self.status.lock() = status;
}
...
}
Support the current function
Because at any given time, only one thread could be in Running state. Therefore, the easiest way is to record it in the Manager struct. The current function could thus be implemented:
File: src/thread/manager.rs
/// Global thread manager, contains a scheduler and a current thread.
pub struct Manager {
/// The current running thread
pub current: Mutex<Arc<Thread>>,
/// All alive and not yet destroyed threads
all: Mutex<VecDeque<Arc<Thread>>>,
}
File: src/thread.rs
/// Get the current running thread
pub fn current() -> Arc<Thread> {
Manager::get().current.lock().clone()
}
The Schedule trait and the FIFO Scheduler
When a thread yields, the OS is responsible to select another ready thread and schedule it. Many algorithms can achieve this. Therefore, we designed the Schedule trait to standardize it.
File: src/thread/scheduler.rs
/// Basic thread scheduler functionalities.
pub trait Schedule: Default {
/// Notify the scheduler that a thread is able to run. Then, this thread
/// becomes a candidate of [`schedule`](Schedule::schedule).
fn register(&mut self, thread: Arc<Thread>);
/// Choose the next thread to run. `None` if scheduler decides to keep running
/// the current thread.
fn schedule(&mut self) -> Option<Arc<Thread>>;
}
The Schedule trait looks nice, but how to use it? In fact, we added a new field, scheduler in the Manager struct, who will use scheduler to select from the thread candidates, and record the ready threads. For example, when a new thread is created, its default state is Ready. So the Manager will call scheduler to register it into the scheduler.
File: src/thread/manager.rs
/// Global thread manager, contains a scheduler and a current thread.
pub struct Manager {
/// Global thread scheduler
pub scheduler: Mutex<Scheduler>,
/// The current running thread
pub current: Mutex<Arc<Thread>>,
/// All alive and not yet destroyed threads
all: Mutex<VecDeque<Arc<Thread>>>,
}
impl Manager {
/// Get the singleton.
pub fn get() -> &'static Self { ... }
pub fn register(&self, thread: Arc<Thread>) {
// Register it into the scheduler
self.scheduler.lock().register(thread.clone());
// Store it in all list.
self.all.lock().push_back(thread.clone());
}
}
Implement a scheduler is easy (at least for FIFO scheduler):
// File: src/thread/scheduler/fcfs.rs
/// FIFO scheduler.
#[derive(Default)]
pub struct Fcfs(VecDeque<Arc<Thread>>);
impl Schedule for Fcfs {
fn register(&mut self, thread: Arc<Thread>) {
self.0.push_front(thread)
}
fn schedule(&mut self) -> Option<Arc<Thread>> {
self.0.pop_back()
}
}
To use the FIFO scheduler, we need to create a type alias:
// File: src/thread/scheduler.rs
pub type Scheduler = self::fcfs::Fcfs;
The Schedule trait allows us to separate the logic of context switching and selecting candidate execution threads. Manager only uses Schedule trait, if you want to use another scheduler, all you need to do is to create another struct, implement Schedule trait, and set the type as Scheduler. Isn't it exciting?
Support schedule function based on Schedule trait
Now we are writing the schedule function. Suppose there are two kernel threads, T1 and T2. T1 calls schedule(), and the scheduler choose T2 to run. Basically, schedule must:
- store callee-saved register values on T1's context (we needn't store caller saved values, because they have already saved in stack frame)
- load T2'2 register values from T2's context (including load T2's sp)
- transfer control to T2's PC
- update information in
Manager
Following graph shows the sp before & after the schedule.
Before schedule After schedule
┌──────────────┐ ┌──────────────┐
│ ... │ │ ... │
├──────────────┤ ├──────────────┤
sp-> │ T1's stack │ │ T1's stack │
├──────────────┤ ├──────────────┤
│ ... │ │ ... │
├──────────────┤ ├──────────────┤
│ T2's stack │ sp->│ T2's stack │
├──────────────┤ ├──────────────┤
│ ... │ │ ... │
└──────────────┘ └──────────────┘
We divided the schedule function into 3 steps:
- Use scheduler to find another runnable thread
- Do context switching
- Do some finishing touches, like register the previous thread to the scheduler, ...
The first and third step needs to modify the Manager or the Scheduler, therefore they are implemented as a method of Manager. The second step has to be written in assembly. Let's start from the first step:
// File: src/thread/manager.rs
impl Manager {
...
pub fn schedule(&self) {
let next = self.scheduler.lock().schedule();
if let Some(next) = next {
assert_eq!(next.status(), Status::Ready);
next.set_status(Status::Running);
// Update the current thread to the next running thread
let previous = mem::replace(self.current.lock().deref_mut(), next);
// Retrieve the raw pointers of two threads' context
let old_ctx = previous.context();
let new_ctx = self.current.lock().context();
// WARNING: This function call may not return, so don't expect any value to be dropped.
unsafe { switch::switch(Arc::into_raw(previous).cast(), old_ctx, new_ctx) }
// Back to this location (which `ra` points to), indicating that another thread
// has yielded its control or simply exited. Also, it means now the running
// thread has been shceudled for more than one time, otherwise it would return
// to `kernel_thread_entry` (See `create` where the initial context is set).
}
}
}
The first step is done in Manager::schedule function. We first find another runnable thread. If success, we marked it as Running, put it inside the current field, and then call switch to do context switching. The switch function takes 3 arguments: an pointer to the previous thread, and the old_ctx and new_ctx. old_ctx and new_ctx are preserved context in previous and current Thread struct.
The next step is in the switch funtion. switch is written in riscv asm, and we prepared a signiture for it in rust extern "C", in order to force it to stick to the C calling convention (a0~a7 are arguments, ...):
File: src/thread/switch.rs
#[allow(improper_ctypes)]
extern "C" {
/// Save current registers in old. Load from new.
///
/// The first argument is not used in this function, but it
/// will be forwarded to [`schedule_tail_wrapper`].
pub fn switch(previous: *const Thread, old: *mut Context, new: *mut Context);
}
global_asm! {r#"
.section .text
.globl switch
switch:
sd ra, 0x0(a1)
ld ra, 0x0(a2)
sd sp, 0x8(a1)
ld sp, 0x8(a2)
sd s0, 0x10(a1)
ld s0, 0x10(a2)
sd s1, 0x18(a1)
ld s1, 0x18(a2)
sd s2, 0x20(a1)
ld s2, 0x20(a2)
sd s3, 0x28(a1)
ld s3, 0x28(a2)
sd s4, 0x30(a1)
ld s4, 0x30(a2)
sd s5, 0x38(a1)
ld s5, 0x38(a2)
sd s6, 0x40(a1)
ld s6, 0x40(a2)
sd s7, 0x48(a1)
ld s7, 0x48(a2)
sd s8, 0x50(a1)
ld s8, 0x50(a2)
sd s9, 0x58(a1)
ld s9, 0x58(a2)
sd s10, 0x60(a1)
ld s10, 0x60(a2)
sd s11, 0x68(a1)
ld s11, 0x68(a2)
j schedule_tail_wrapper
"#}
/// A thin wrapper over [`thread::Manager::schedule_tail`]
///
/// Note: Stack is not properly built in [`switch`]. Therefore,
/// this function should never be inlined.
#[no_mangle]
#[inline(never)]
extern "C" fn schedule_tail_wrapper(previous: *const Thread) {
Manager::get().schedule_tail(unsafe { Arc::from_raw(previous) });
}
old is the previous thread's context, we will write to it; new is the next thread's context, we will read from it. The switch function changes the runtime stack. Then we jump to the schedule_tail_wrapper, where we call the Manager::schedule_tail, finish the schedule procedure:
File: src/thread/manager.rs
impl Manager {
/// Note: This function is running on the stack of the new thread.
pub fn schedule_tail(&self, previous: Arc<Thread>) {
match previous.status() {
Status::Dying => {
// A thread's resources should be released at this point
self.all.lock().retain(|t| t.id() != previous.id());
}
Status::Running => {
previous.set_status(Status::Ready);
self.scheduler.lock().register(previous);
}
Status::Blocked => {}
Status::Ready => unreachable!(),
}
}
}
We will do different work, depending on the status of the previous thread. Let's focus on the Running and Ready cases (we will come back to Dying when discuss the exit funtion, and discuss Blocked in further future). The previous thread's status is Ready is a unreachable case, beacuse it is read from the current field in the Manager, so it should not be ready. Previous thread's status is Running indicates it yields the CPU, then we shall put it back into the scheduler.
After schedule_tail finishes, we have already done everything needed to switch to another thread. Then schedule_tail should return to schedule_tail_wrapper, which should return to somewhere in the new thread, and continues to execute it. It actually does so, because we have already modified the ra register in switch (MAGIC!).
Exercise
In fact,
schedule_tail_wrapperonly returns to two places. Could you find them?
With three functions introduced above, the schedule funtion could be implemented in this way:
File: src/thread.rs
/// Yield the control to another thread (if there's another one ready to run).
pub fn schedule() {
Manager::get().schedule()
}
Support exit function
In schedule_tail, the status matches Dying means the previous function is exited. Therefore, in the exit function, all we need to do is to set the status to Dying, and then schedule another funtion.
File: src/thread.rs
/// Gracefully shut down the current thread, and schedule another one.
pub fn exit() -> ! {
{
let current = Manager::get().current.lock();
current.set_status(Status::Dying);
}
schedule();
unreachable!("An exited thread shouldn't be scheduled again");
}
Exercise
Why do we need another block before calling
schedule? If we delete the "{" and "}" inside the function, what will happen?
Enable Preemptive Scheduling
We have already built basic thread interfaces. However, current implementation has a problem: if a thread never yields, other threads will be unable to make progress, which is unfair. Enable timer interrupt is a solution: after each interrupt happens, we call schedule(), force it to yield CPU to another thread (The scheduler will decide who runs next). This chapter is highly related to riscv's priviledge ISA. If you are unfamiliar with some CSRs(Control and Status Register) or some instructions(e.g. sret, ...), please refer to riscv's Priviledged Specifications. This website could also be helpful.
Interrupts, Exceptions, and Traps
In riscv, interrupts are external asynchronous events, while exceptions are unusual conditions occurring at run time associated with an instruction in the current RISC-V hart. Interrupts and exceptions may cause the hart to experience an unexpected transfer of control. By definition, timer interrupt is a kind of interrupt. Unlike x86, where trap is a class of exceptions, trap refers to the transfer of control flow in riscv. When an interrupt or exception happens in rv64 (in Supervisor mode, where OS runs), following CSRs are effective:
stvec(Supervisor Trap Vector Base Address Register):stvecspecifies the base address of the trap vector, and the trap mode (vectored or direct)sstatus(Supervisor Status Register):sstatushas a bit namedSIE, whose value decides whether interrupts in supervisor mode are enabled. Exceptions are always enabled.sie(Supervisor interrupt-enable register):siehas three bits:SEIE,STIEandSSIE, they decide whether External, Timer and Software interrupts are enabled in supervisor mode
For example, when a timer interrupt happens, if sstatus.SIE=1 and sie.STIE=1, then a trap happens, and the control will be transfered (i.e. PC will be set) to the address stored in stvec. When a trap happens, following CSRs are changed:
sstatus:sstatushas another bit namedSPIE, whose values will be set to the value ofsstatus.SIEbefore the trap happens.sstatus.SIEwill be set to 0.scause: setscauseregister to the cause of this trap. For example, if it is a timer interrupt, thenscause=TIMER_INTERRUPT_IDsepc: will be set to the PC's value before the trap happens
After that, we will run the trap handler code. For example, when a timer interrupt happens and traps, we probably want to schedule another kernel thread. After the interrupt is handled, the standard way to exit the interrupt context is to use the sret instruction, which performs following operations:
- set
sstatus.SIEto the value ofsstatus.SPIE, and setsstatus.SPIEto 0 - set PC to the value of
sepc, and setsepcto 0
We will enable timer interrupt in Tacos by using above features in riscv. Fortunately, the riscv crate capsules many riscv priviledged instructions, we don't have to write everything in assembly.
Enable/Disable Interrupts, and set timer interval
Timer interrupts are not enabled automatically, we need to turn it on manually. Sometimes we want to turn it down to synchronize. Turn on/off the interrupt can be done by modifying sstatus or sie CSR. We choose to modify the sie register:
File: src/sbi/interrupt.rs
#[inline]
fn on() {
unsafe {
register::sie::set_stimer();
};
}
#[inline]
fn off() {
unsafe {
register::sie::clear_stimer();
};
}
/// Get timer & external interrupt level. `true` means interruptible.
#[inline]
pub fn get() -> bool {
register::sie::read().stimer()
}
/// Set timer & external interrupt level.
pub fn set(level: bool) -> bool {
let old = get();
// To avoid unnecessary overhead, we only (un)set timer when its status need
// to be changed. Synchronization is not used between `get` and `on/off`, as
// data race only happens when timer is on, and timer status should have been
// restored before the preemptor yields.
if old != level {
if level {
on();
} else {
off();
}
}
old
}
In riscv, two CSRs decide the behavior of timer interrupt:
mtime: the value ofmtimeincrement at constant frequency. The frequency is known on qemu (12500000 per second)mtimecmp: whenmtimeis greater thanmtimecmp, a timer interrupt is generated
We could use sbi calls to read mtime register:
File: src/sbi/timer.rs
pub const CLOCK_PRE_SEC: usize = 12500000;
/// Get current clock cycle
#[inline]
pub fn clock() -> usize {
riscv::register::time::read()
}
/// Get current time in milliseconds
#[inline]
pub fn time_ms() -> usize {
clock() * 1_000 / CLOCK_PRE_SEC
}
/// Get current time in microseconds
#[inline]
pub fn time_us() -> usize {
clock() * 1_000_000 / CLOCK_PRE_SEC
}
or write mtimecmp register. Following code modifies the mtimecmp register to trigger a timer interrupt after 100ms = 0.1s.
File: src/sbi/timer.rs
/// Set the next moment when timer interrupt should happen
use crate::sbi::set_timer;
pub const TICKS_PER_SEC: usize = 10;
#[inline]
pub fn next() {
set_timer(clock() + CLOCK_PRE_SEC / TICKS_PER_SEC);
}
Trap Handler
Normally a trap handler contains 3 steps:
- preserve the current context
- handles the trap
- recover the context
Let's start with context preservation and recovery. A trap may be caused by an interrupt or an exception. When it is caused by an interrupt, it happens asychronously, which means a thread cannot expect the time when the interrupt happens. When a timer interrupt happens, if the current thread is not finished, we definitely want to resume the execution after the interrupt is handled. Therefore, every general purpose registers must be preserved. The trap process and the sret instruction uses sepc and sstatus, we should preserve them as well (if we want to support nested interrupt, which is inevitable in supporting preemptive scheduling). We use the Frame struct to preserve the context:
File: src/trap.rs
#[repr(C)]
/// Trap context
pub struct Frame {
/// General regs[0..31].
pub x: [usize; 32],
/// CSR sstatus.
pub sstatus: Sstatus,
/// CSR sepc.
pub sepc: usize,
}
And use following assembly code to preserve it, and pass a mutable reference to the trap_handler function in the a0 register:
File: src/trap.rs
arch::global_asm! {r#"
.section .text
.globl trap_entry
.globl trap_exit
.align 2 # Address of trap handlers must be 4-byte aligned.
trap_entry:
addi sp, sp, -34*8
# save general-purpose registers
# sd x0, 0*8(sp)
sd x1, 1*8(sp)
# sd x2, 2*8(sp)
sd x3, 3*8(sp)
sd x4, 4*8(sp)
sd x5, 5*8(sp)
sd x6, 6*8(sp)
sd x7, 7*8(sp)
sd x8, 8*8(sp)
sd x9, 9*8(sp)
sd x10, 10*8(sp)
sd x11, 11*8(sp)
sd x12, 12*8(sp)
sd x13, 13*8(sp)
sd x14, 14*8(sp)
sd x15, 15*8(sp)
sd x16, 16*8(sp)
sd x17, 17*8(sp)
sd x18, 18*8(sp)
sd x19, 19*8(sp)
sd x20, 20*8(sp)
sd x21, 21*8(sp)
sd x22, 22*8(sp)
sd x23, 23*8(sp)
sd x24, 24*8(sp)
sd x25, 25*8(sp)
sd x26, 26*8(sp)
sd x27, 27*8(sp)
sd x28, 28*8(sp)
sd x29, 29*8(sp)
sd x30, 30*8(sp)
sd x31, 31*8(sp)
# save sstatus & sepc
csrr t0, sstatus
csrr t1, sepc
sd t0, 32*8(sp)
sd t1, 33*8(sp)
mv a0, sp
call trap_handler
trap_exit:
# load sstatus & sepc
ld t0, 32*8(sp)
ld t1, 33*8(sp)
csrw sstatus, t0
csrw sepc, t1
# load general-purpose registers
# ld x0, 0*8(sp)
ld x1, 1*8(sp)
# ld x2, 2*8(sp)
ld x3, 3*8(sp)
ld x4, 4*8(sp)
ld x5, 5*8(sp)
ld x6, 6*8(sp)
ld x7, 7*8(sp)
ld x8, 8*8(sp)
ld x9, 9*8(sp)
ld x10, 10*8(sp)
ld x11, 11*8(sp)
ld x12, 12*8(sp)
ld x13, 13*8(sp)
ld x14, 14*8(sp)
ld x15, 15*8(sp)
ld x16, 16*8(sp)
ld x17, 17*8(sp)
ld x18, 18*8(sp)
ld x19, 19*8(sp)
ld x20, 20*8(sp)
ld x21, 21*8(sp)
ld x22, 22*8(sp)
ld x23, 23*8(sp)
ld x24, 24*8(sp)
ld x25, 25*8(sp)
ld x26, 26*8(sp)
ld x27, 27*8(sp)
ld x28, 28*8(sp)
ld x29, 29*8(sp)
ld x30, 30*8(sp)
ld x31, 31*8(sp)
addi sp, sp, 34*8
sret
"#}
Before the trap_exit part, we called trap_handler, which is used to handle the interrupt or exception. When a trap happens, the
File: src/trap.rs
use riscv::register::scause::{
Exception::{self, *},
Interrupt::*,
Trap::*,
};
use riscv::register::sstatus::*;
use riscv::register::*;
#[no_mangle]
pub extern "C" fn trap_handler(frame: &mut Frame) {
let scause = scause::read().cause();
let stval = stval::read();
match scause {
Interrupt(SupervisorTimer) => {
sbi::timer::tick();
unsafe { riscv::register::sstatus::set_sie() };
thread::schedule();
}
_ => {
unimplemented!(
"Unsupported trap {:?}, stval={:#x}, sepc={:#x}",
scause,
stval,
frame.sepc,
)
}
}
}
Currently we only handle timer interrupts. Other interrupts/exceptions will be added with IO devices or user programs. We handle the timer interrupt in this way: first, we call tick to update the TICKS static variable, and call next reset the mtimecmp register:
File: src/sbi/timer.rs
static TICKS: AtomicI64 = AtomicI64::new(0);
/// Returns the number of timer ticks since booted.
pub fn timer_ticks() -> i64 {
TICKS.load(SeqCst)
}
/// Update [`TICKS`] and set the next timer interrupt
pub fn tick() {
TICKS.fetch_add(1, SeqCst);
next();
}
Remember that when a trap happens, the sstatus.SIE will be set to 0. We then set it back to 1. After that, we simplt call schedule() to enforce the current thread to yield the CPU to another thread.
Congratulations! Now we have supported preemptive scheduling in Tacos. But the introduction of interrupts may cause problems with some of the original implementations. We need to resolve them with synchronizations.
Synchronization
The implementation of the thread Manager need change after interrupts are enabled, we need to explicitly synchronize the schedule part. Kernel threads are running concurrently, synchronization enables them to cooperate. Therefore, synchronization primitives, such as Mutexs, should be implemented to help the kernel development.
Update Manager: Synchronize by turning on/off the interrupts
After interrupts are turned on, timer interrupts could happen at any time. Interrupts happen in some critical sections may cause unexpected behaviors. For example, the schedule method will modify the global Manager's states. We clearly do not want be interrupted when the kernel is changing those states (e.g. in Manager.schedule()). Therefore, we could disable the interrupt before the critical section, and restore the interrupt setting when the thread is scheduled again:
File: src/thread/manager.rs
impl Manager {
pub fn schedule(&self) {
let old = interrupt::set(false);
... // original implementation
// Back to this location indicating that the running thread has been shceudled.
interrupt::set(old);
}
}
All threads should enable interrupt before entering:
File: src/thread/imp.rs
#[no_mangle]
extern "C" fn kernel_thread(main: *mut Box<dyn FnOnce()>) -> ! {
interrupt::set(true);
...
}
Implement Semaphore: Synchronize by blocking waiter threads
The implementation of Semaphore needs the block function, which will block the current thread and yield the CPU. The blocked thread can be waken by another thread:
/// Mark the current thread as [`Blocked`](Status::Blocked) and
/// yield the control to another thread
pub fn block() {
let current = current();
current.set_status(Status::Blocked);
schedule();
}
/// Wake up a previously blocked thread, mark it as [`Ready`](Status::Ready),
/// and register it into the scheduler.
pub fn wake_up(thread: Arc<Thread>) {
assert_eq!(thread.status(), Status::Blocked);
thread.set_status(Status::Ready);
Manager::get().scheduler.lock().register(thread);
}
With block and wake_up, Semaphore could be implemented in this way:
File: src/sync/sema.rs
pub struct Semaphore {
value: Cell<usize>,
waiters: RefCell<VecDeque<Arc<Thread>>>,
}
unsafe impl Sync for Semaphore {}
unsafe impl Send for Semaphore {}
impl Semaphore {
/// Creates a new semaphore of initial value n.
pub const fn new(n: usize) -> Self {
Semaphore {
value: Cell::new(n),
waiters: RefCell::new(VecDeque::new()),
}
}
/// P operation
pub fn down(&self) {
let old = sbi::interrupt::set(false);
// Is semaphore available?
while self.value() == 0 {
// `push_front` ensures to wake up threads in a fifo manner
self.waiters.borrow_mut().push_front(thread::current());
// Block the current thread until it's awakened by an `up` operation
thread::block();
}
self.value.set(self.value() - 1);
sbi::interrupt::set(old);
}
/// V operation
pub fn up(&self) {
let old = sbi::interrupt::set(false);
let count = self.value.replace(self.value() + 1);
// Check if we need to wake up a sleeping waiter
if let Some(thread) = self.waiters.borrow_mut().pop_back() {
assert_eq!(count, 0);
thread::wake_up(thread.clone());
}
sbi::interrupt::set(old);
}
/// Get the current value of a semaphore
pub fn value(&self) -> usize {
self.value.get()
}
}
Semaphore contains a value and a vector of waiters. The down operation may cause a thread to block, if so, the following up operations are responsible to wake it up. To use the Semaphore in different threads, we need it to be Sync and Send. It is obvious Send, because Cell and Refcell are Send. What about Sync? Fortunately it is indeed Sync, because we disable interrupts when modifying the cells -- otherwise a struct contains a cell is not, in most cases, Sync.
Implement locks and Mutex: Synchronize by disabling interrupt, spining or blocking waiter threads
We uses Mutex very frequently in Tacos, but we haven't implemented it yet. To build Mutex, we need to take a look at locks first. Locks support two types of operations: acquire and release. When a lock is initialized, it is free (i.e. could be acquired). A lock will be held until it explicitly releases it. Following trait illustrates the interface of lock:
pub trait Lock: Default + Sync + 'static {
fn acquire(&self);
fn release(&self);
}
There are three different ways to implement this trait, the first (and the simplest) way is to change the interrupt status. The Intr struct implements the Lock trait:
File: src/sync/intr.rs
#[derive(Debug, Default)]
pub struct Intr(Cell<Option<bool>>);
impl Intr {
pub const fn new() -> Self {
Self(Cell::new(None))
}
}
impl Lock for Intr {
fn acquire(&self) {
assert!(self.0.get().is_none());
// Record the old timer status. Here setting the immutable `self` is safe
// because the interrupt is already turned off.
self.0.set(Some(sbi::interrupt::set(false)));
}
fn release(&self) {
sbi::interrupt::set(self.0.take().expect("release before acquire"));
}
}
unsafe impl Sync for Intr {}
Exercise
Intris aCell. Is it safe to implementSyncfor it?
The Spin struct shows a spinlock implementation. Since AtomicBool is Sync and Send, it could be automatically derived:
File: src/sync/spin.rs
#[derive(Debug, Default)]
pub struct Spin(AtomicBool);
impl Spin {
pub const fn new() -> Self {
Self(AtomicBool::new(false))
}
}
impl Lock for Spin {
fn acquire(&self) {
while self.0.fetch_or(true, SeqCst) {
assert!(interrupt::get(), "may block");
}
}
fn release(&self) {
self.0.store(false, SeqCst);
}
}
We could also let the waiters block. In fact, we could just reuse Semaphore:
File: src/sync/sleep.rs
#[derive(Clone)]
pub struct Sleep {
inner: Semaphore,
}
impl Default for Sleep {
fn default() -> Self {
Self {
inner: Semaphore::new(1),
}
}
}
impl Lock for Sleep {
fn acquire(&self) {
self.inner.down();
}
fn release(&self) {
self.inner.up();
}
}
unsafe impl Sync for Sleep {}
Based on Locks, build a Mutex is easy. A Mutex contains the real data (encapsuled in a cell to gain innter mutability), and a lock. The lock method acquires the lock and returns the MutexGuard. The MutexGuard is a smart pointer, and could be auto-dereferenced to data's type. On drop, the MutexGuard releases the lock:
File: src/sync/mutex.rs
#[derive(Debug, Default)]
pub struct Mutex<T, L: Lock = sync::Primitive> {
value: UnsafeCell<T>,
lock: L,
}
// The only access to a Mutex's value is MutexGuard, so safety is guaranteed here.
// Requiring T to be Send-able prohibits implementing Sync for types like Mutex<*mut T>.
unsafe impl<T: Send, L: Lock> Sync for Mutex<T, L> {}
unsafe impl<T: Send, L: Lock> Send for Mutex<T, L> {}
impl<T, L: Lock> Mutex<T, L> {
/// Creates a mutex in an unlocked state ready for use.
pub fn new(value: T) -> Self {
Self {
value: UnsafeCell::new(value),
lock: L::default(),
}
}
/// Acquires a mutex, blocking the current thread until it is able to do so.
pub fn lock(&self) -> MutexGuard<'_, T, L> {
self.lock.acquire();
MutexGuard(self)
}
}
/// An RAII implementation of a “scoped lock” of a mutex.
/// When this structure is dropped (falls out of scope), the lock will be unlocked.
///
/// The data protected by the mutex can be accessed through
/// this guard via its Deref and DerefMut implementations.
pub struct MutexGuard<'a, T, L: Lock>(&'a Mutex<T, L>);
unsafe impl<T: Sync, L: Lock> Sync for MutexGuard<'_, T, L> {}
impl<T, L: Lock> Deref for MutexGuard<'_, T, L> {
type Target = T;
fn deref(&self) -> &T {
unsafe { &*self.0.value.get() }
}
}
impl<T, L: Lock> DerefMut for MutexGuard<'_, T, L> {
fn deref_mut(&mut self) -> &mut T {
unsafe { &mut *self.0.value.get() }
}
}
impl<T, L: Lock> Drop for MutexGuard<'_, T, L> {
fn drop(&mut self) {
self.0.lock.release();
}
}
Implement condition variable
Rust std crate provides an implementation of conditional variable. Following implementation is heavily influenced by the std version:
File: src/sync/condvar.rs
pub struct Condvar(RefCell<VecDeque<Arc<Semaphore>>>);
unsafe impl Sync for Condvar {}
unsafe impl Send for Condvar {}
impl Condvar {
pub fn new() -> Self {
Condvar(Default::default())
}
pub fn wait<T, L: Lock>(&self, guard: &mut MutexGuard<'_, T, L>) {
let sema = Arc::new(Semaphore::new(0));
self.0.borrow_mut().push_front(sema.clone());
guard.release();
sema.down();
guard.acquire();
}
/// Wake up one thread from the waiting list
pub fn notify_one(&self) {
self.0.borrow_mut().pop_back().unwrap().up();
}
/// Wake up all waiting threads
pub fn notify_all(&self) {
self.0.borrow().iter().for_each(|s| s.up());
self.0.borrow_mut().clear();
}
}
A tricky part is that we need to release and re-acquire the lock when we are using it to wait for a condition. The wait method takes a MutexGuard as the argument. Therefore, we implement release and acquire for MutexGuard:
File: src/sync/mutex.rs
// Useful in Condvar
impl<T, L: Lock> MutexGuard<'_, T, L> {
pub(super) fn release(&self) {
self.0.lock.release();
}
pub(super) fn acquire(&self) {
self.0.lock.acquire();
}
}
OnceCell and Lazy: Ensure global values are initialized once
Rust discourages mutable global variables -- they are naturally referenced by mutiple threads, thus must be Sync. But we do need global variables, and we may need runtime information (e.g. DRAM size) to properly initialize it. OnceCell and Lazy is the solution. Like Condvar, they exist in std library, and the current implementation is influenced by std version. Because it is not highly related to the labs, we just give some examples and omit the details of the implementation. You are free to read it under the src/kernel/sync/ directory.
We used Manager::get() to access the singleton in this chapter, and we didn't discuss the implementation in previous sections, because the implementation of get used Lazy to lazily initialize the static variable. We take the current running thread as the "Initial" thread, create the idle thread, and build the global TMANAGER:
File: src/thread/manager.rs
impl Manager {
pub fn get() -> &'static Self {
static TMANAGER: Lazy<Manager> = Lazy::new(|| {
let initial = Arc::new(Thread::new("Initial", 0, PRI_DEFAULT, 0, None, None));
initial.set_status(Status::Running);
let manager = Manager {
scheduler: Mutex::new(Scheduler::default()),
all: Mutex::new(VecDeque::from([initial.clone()])),
current: Mutex::new(initial),
};
// Thread builder is not ready, we must manually build idle thread.
let function: *mut Box<dyn FnOnce()> = Box::into_raw(Box::new(Box::new(|| loop {
schedule()
})));
let stack = kalloc(STACK_SIZE, STACK_ALIGN) as usize;
let idle = Arc::new(Thread::new(
"idle",
stack,
function as usize,
));
manager.register(idle);
manager
});
&TMANAGER
}
}
Appetizer
Deadline & Submission
Code Due: Thursday 03/12 11:59pm
- Use
make submissionto tarball and compress your code assubmission.tar.bz2- Change the name of submission.tar.bz2 to
submission_yourStudentID.tar.bz2, e.g.,submission_20000xxxxx.tar.bz2- Submit this file to the
Lab0: Getting Realon PKU course websiteDesign Doc Due: Sunday 03/15 11:59pm
- Submit your design document as a PDF to the
Lab0: Design Docon PKU course website
This assignment is set to prepare you for the later Tacos projects. It will walk you through what happened after a PC is powered on till when an operating system is up and running, which you may have wondered about before.
Throughout this project, you will:
- set up the development environment and run/debug Tacos it in QEMU
- trace the boot process and get familiar with the codebase
- do a simple programming exercise to add a tiny kernel monitor to Tacos
Note that this assignment is much simpler than the remaining projects, because it is intentionally designed to help you warm up.
Tasks
Enviroment preparation
Read the Install toolchain section to set up your local development environment and get familiar with the course project.
Design Doc
Download the design document template of lab 0. Read through questions in the document to get a feel for the lab before you start, and answer them as you go.
Booting Tacos
If you have set up the Tacos development environment as described in the Install toolchain section, you should see Tacos booting in the QEMU emulator, and print SBI messages, "Hello, world!" and "Goodbye, world!". Take screenshots of the successful booting of Tacos in QEMU.
Debugging
While you are working on the projects, you will frequently use the GNU Debugger (GDB) to help you find bugs in your code. Make sure you read the Debugging section first. In addition, if you are unfamiliar with RISC-V assembly, the RISC-V Instruction Set Manual is an excellent reference. Some online resources, such as Five Embeddev, are also available.
In this section, you will use GDB to trace the QEMU emulation to understand how Tacos boots. Follow the steps below and answer the questions in your design document:
- Figure out the right command to start Tacos, freeze it, and use gdb-multiarch to connect to the guest kernel.
Question
- What is the first instruction that gets executed?
- At which physical address is this instruction located?
Note: Zero Stage Bootloader (ZSBL)
If you use commands in Debugging to start Tacos & freeze Tacos's execution, QEMU will wait at the very first instruction, which will be executed by the machine later. The first few executed instructions are called (at least in the RISC-V world) the Zero Stage Bootloader (ZSBL). In real machines, the ZSBL is most likely located in a ROM firmware on the board. The ZSBL reads some machine information, initializes a few registers based on them, and then passes control to SBI using
jmpinstructions.
- QEMU's ZSBL only contains a few (less than 20) instructions, and ends with a
jmpinstruction. Use gdb to trace the ZSBL's execution.
Question
- Which address will the ZSBL jump to?
- Before entering the
mainfunction inmain.rs, the SBI would have already generated some output. Use breakpoints to stop the execution at the beginning of themainfunction. Read the output and answer the following questions:
Question
- What are the values of the arguments
hart_idanddtb?- What are the values of
Domain0 Next Address,Domain0 Next Arg1,Domain0 Next ModeandBoot HART IDin OpenSBI's output?- What's the relationship between the four output values and the two arguments?
- The functionality of SBI is basically the same as BIOS. e.g. When Tacos kernel wants to output some string to the console, it simply invokes interfaces provided by SBI. Tacos uses OpenSBI, an open source RISC-V SBI implementation. Trace the execution of
console_putcharinsbi.rs, and answer the following questions:
Question
- Inside
console_putchar, Tacos uses theecallinstruction to transfer control to SBI. What are the values of registera6and registera7when executing thatecall?
Kernel Monitor
Finally, you will get to make a small enhancement to Tacos and write some code!
Note: Features in Tacos
- When compiled with different features, Tacos can do more than just printing "Hello, world!".
- For example, if
testfeature is enabled, Tacos will check for the supplied command line arguments stored in the kernel image. Typically you will pass some tests for the kernel to run.- There is another feature named
shell. To build and run the kernel withshellfeature, you could usecargo run -F shell.
Currently, the kernel simply terminates after booting. This is a little boring. Your task is to add a tiny kernel shell to Tacos so that when compiled with the shell feature, Tacos will run this shell interactively.
Note: Kernel shell
- You will implement a kernel-level shell. In later projects, you will be enhancing the user program and file system parts of Tacos, at which point you will get to run the regular shell.
- You only need to make this monitor very simple. The requirements are described below.
Requirements:
- Enhance
main.rsto implement a tiny kernel monitor in Tacos. - It starts with a prompt
PKUOS>and waits for user input. - When a newline is entered, it parses the input and checks if it is
whoami. If it iswhoami, print your student id. Afterward, the monitor will print the command promptPKUOS>again in the next line and repeat. - If the user input is
exit, the monitor will quit to allow the kernel to finish. For other inputs, print invalid command.
Hint
- The code place for you to add this feature is in
main.rs:// TODO: Lab 0- You may find some interfaces in
sbi.rsto be very useful for this lab.
Scheduling
Deadline & Submission
Code Due: Thursday 04/02 11:59pm
- Use
make submissionto tarball and compress your code assubmission.tar.bz2- Change the name of submission.tar.bz2 to
submission_yourStudentID.tar.bz2, e.g.,submission_20000xxxxx.tar.bz2- Submit this file to the
Lab1: Threadson PKU course websiteDesign Doc Due: Sunday 04/05 11:59pm
- Submit your design document as a PDF to the
Lab1: Design Docon PKU course website
In this assignment, we give you a minimally functional thread system. Your job is to extend the functionality of this system to support priority scheduling. You will gain a better understanding of synchronization problems after finishing this project.
You will focus on the code under the thread/ directory.
To complete this lab, the first step is to read and understand the code for the initial thread system. Tacos already implements thread creation and thread completion, a FIFO scheduler to switch between threads, and synchronization primitives (semaphores, locks, condition variables). Some of the code might seem slightly mysterious. You can read through the kernel thread part to see what's going on.
Tasks
Note
Please synchronize your code base with our remote repository before you start this lab.
Design Doc
Download the design document template of project 1. Read through questions in the document for motivations, and fill it in afterwards.
Alarm Clock
Reimplement sleep() in kernel/thread.rs to avoid busy waiting. The prototype of sleep() is:
// src/kernel/thread.rs
pub fn sleep(ticks: i64)
The sleep() function:
- Suspends execution of the calling thread until time has advanced by at least
tickstimer ticks. - Unless the system is otherwise idle, the thread need not wake up after exactly ticks. Just put it on the ready queue after they have waited for the right amount of time.
- The argument to
sleep()is expressed in timer ticks, not in milliseconds or any another unit. There areTICKS_PER_SECtimer ticks per second, whereTICKS_PER_SECis a const value defined insbi/timer.rs. The default value is 10. We don't recommend changing this value, because any change is likely to cause many of the tests to fail.
Note
In Windows and Linux, the
sleepfunction may block for longer than the requested time due to scheduling or resource contention delays. In fact, only real-time operating systems(RTOS) could guarantee exact sleep interval. In practice, if you do need fine-grained timing control, it is better to sleep for a bit less than the amount of time you want to wait for, and then wake up and spin.
sleep() is useful for threads that operate in real-time, e.g. for blinking the cursor once per second. Although a working implementation is provided, it "busy waits," that is, it spins in a loop checking the current time and calling schedule() until enough time has gone by. You are supposed to reimplement it to avoid busy waiting.
The alarm clock implementation is not needed for other parts of this project. But it is still suggested to implement the alarm clock first.
Hint
You need to decide where to check whether the elapsed time exceeded the sleep time.
- The original
sleep()implementation callstimer_ticks(), which returns the current ticks.- You may want to check where the static
TICKSvariable insrc/sbi/timer.rsis updated.
Hint
- You may want to leverage some synchronization primitives that provides some sort of thread "waiting" functionality, e.g., semaphore.
- In addition, when modifying some global variable, you will need to use some synchronized data structures to ensure it is not modified or read concurrently (e.g., a timer interrupt occurs during the modification and we switch to run another thread). You may find
Mutexstruct inplemented insrc/kernel/sync/mutex.rsto be useful in this project, and the following ones.
Hint
You may find some data structures provided by
alloccrate to be useful in this project, and the following ones.
- The
alloccrate providesVec,VecDeque,BTreeMapand many useful data structures. As you may have noticed, the FIFO scheduler usesVecDeque.- Feel free to choose appropriate data structures to support your design!
Priority Scheduling
Basic Priority Scheduling
In Priority Scheduling, thread with higher priority should always go first. If another thread with higher priority is ready to run, the current thread should immediately yield the processor to the new thread. Therefore, your scheduler should ensure that for any ready thread A and B:
- If Priority(A) > Priority(B), A runs (B doesn't).
- If Priority(A) == Priority(B), A and B run in RR (Round Robin).
For example, if a kernel thread A creates another kernel thread B with higher priority, A should immediately yield the processor to B, because A and B are ready, and Priority(A) < Priority(B). Things are similar when some threads are waken up.
Tip
In Tacos, thread priorities range from
PRI_MIN(0) toPRI_MAX(63). Lower numbers correspond to lower priorities, so that priority 0 is the lowest priority and priority 63 is the highest. Each thread has an initial priority after it is created. Most thread usePRI_DEFAULT(31) as its priority. ThePRI_constants are defined insrc/kernel/thread/imp.rs, and you should not change their values.
In addition, for threads that are waiting for a lock, semaphore or condition variable, the highest priority waiting thread should be awakened first. Therefore, you may need to modify implementation of lock, semaphore and condition variable to ensure this.
A thread may also raise or lower its own priority at any time. Lowering its priority such that it no longer has the highest priority must cause it to immediately yield the CPU. In this part, your should also implement set_priority() and get_priority() to support priority changing. Their prototypes are:
/// In src/kernel/thread.rs
pub fn set_priority(_priority: u32)
pub fn get_priority() -> u32
Hint
- For this practice, you need to consider all the scenarios where the priority must be enforced. You can find some of these scenarios by looking for places that uses the
Scheduletrait (directly and indirectly). Look at test cases under thesrc/tests/directory may be helpful.- To yield the CPU, you can check the APIs in
src/kernel/thread.rs.
Priority Donation
One issue with priority scheduling is "priority inversion". Consider high, medium, and low priority threads H, M, and L, respectively. If H needs to wait for L (for instance, for a lock held by L), and M is on the ready list, then H will never get the CPU because the low priority thread will not get any CPU time.
A partial fix for this problem is for H to "donate" its priority to L while L is holding the lock, then recall the donation once L releases (and thus H acquires) the lock. Generally, your scheduler must support following functionality:
- Multiple donations: multiple priorities are donated to a single thread.
- Nested donations: H is waiting on a lock that M holds, and M is waiting on a lock that L holds, then both M and L should be boosted to H's priority.
- Get effective priority: if H is waiting on a lock that L holds, then the
get_priority()called by L should return H's priority.
You are not required to implement priority donations for semaphores. Implement it for locks is enough.
The priority scheduler is not used in any later project.
Testing
Here are all the tests you need to pass to get a full score in lab1:
- alarm-zero
- alarm-negative
- alarm-simultaneous
- alarm-single
- alarm-multiple
- priority-alarm
- priority-change
- priority-condvar
- priority-fifo
- priority-preempt
- priority-sema
- donation-chain
- donation-lower
- donation-nest
- donation-one
- donation-sema
- donation-two
- donation-three
These test cases are recorded in tool/bookmarks/lab1.toml, and you can test the whole lab by
# under tool/
cargo tt -b lab1
To check the expected grade of your current codes, use
# under tool/
cargo grade -b lab1
User Programs
Deadline & Submission
Code Due: Thursday 04/23 11:59pm
- Use
make submissionto tarball and compress your code assubmission.tar.bz2- Change the name of submission.tar.bz2 to
submission_yourStudentID.tar.bz2, e.g.,submission_20000xxxxx.tar.bz2- Submit this file to the
Lab2: User Programson PKU course websiteDesign Doc Due: Sunday 04/26 11:59pm
- Submit your design document as a PDF to the
Lab2: Design Docon PKU course website
Welcome to Project User Programs! You've built great threading features into TacOS. Seriously, that's some great work. This project will have you implement essential syscalls, supporting user programs to run properly on TacOS.
At the moment, the kernel can only load and run simple user programs that do nothing. In order to run more powerful user programs, you are going to implement essential syscalls, for example, enpowering user programs to perform I/O actions, spawning and synchronizing with child processes, and managing files just like what you might do in Linux.
It's not required to complete this assignment on top of the last one, which means you can start freshly from the skeleton code. However, it's still suggested to continue with your previous work so that you can end up having an almost full-featured OS.
Tasks
Suggestion
Please read through this document before working on any task.
Design Document
Download the design document template of project 2. Read through questions in the document for motivations, and fill it in afterwards.
Argument Passing
Currently, the fn execute(mut file: File, argv: Vec<String>) does not pass arguments to new processes. You need to implement it in this task.
- Currently the
argvargument is not used. To implement this functionality, you need to pass theargvto the user program. - The kernel must put the arguments for the initial function on the stack to allow the user program to assess it. The user program will access the arguments following the normal calling convention (see RISC-V calling convention).
- You can impose a reasonable limit on the length of the command line arguments. For example, you could limit the arguments to those that will fit in a single page (4 kB).
Hint
You can parse argument strings any way you like. A viable implementation maybe like:
- Put
Strings in theargvat the top (high address) of the stack. You should terminate those string with"\0"when putting them on the stack.- Push the address of each string (i.e. the contents of user
argv[]) on the stack. Those values are pointers, you should align them to 8 bytes to ensure fast access. Don't forget thatargv[]ends with aNULL.- Prepare the argument
argcandargv, and then deliver them to the user program. They are the first and second arguments ofmain.Here is an argument passing example in 80x86 provided by Pintos. Use the example to help you understand how to set up the stack.
Process Control Syscalls
TacOS currently supports only one syscall — exit, which terminates the calling process. You will add support for the following new syscalls: halt, exec, wait.
Rust has no stable application binary interfaces at the moment. Therefore, all syscalls are represented in C signiture and user programs are also written in C. (Though, it's not hard at all to write a Rust user program if you try.)
The capability of switching in/out of the user mode is well handled by the skeleton code, and arguments passed by users will be forwarded to:
// src/kernel/trap/syscall.rs
pub fn syscall_handler(id: usize, args: [usize; 3]) -> isize
id and args are the number identifier and arguments (at most 3) of the syscall being called, and the return value equals the syscall's return value.
Basically, you dispatch an environment call from users to one of syscalls based on the id. Then, implement each syscall's functionality as described below.
halt
void halt(void);
Terminates TacOS by calling the shutdown function in src/sbi.rs. This should be seldom used, because you lose some information about possible deadlock situations, etc.
exit
void exit(int status);
Terminates the current user program, returning status to the kernel. If the process’s parent waits for it (see below), this is the status that will be returned. Conventionally, a status of 0 indicates success and non-zero values indicate errors.
Note
Every user program that finishes in normally calls exit – even a program that returns from main calls exit indirectly.
exec
int exec(const char* pathname, const char* argv[]);
Runs the executable whose path is given in pathname, passing any given arguments, and returns the new process’s program id (pid). argv is a NULL-terminated array of arguments, where the first argument is usually the executable's name. If the program cannot load or run for any reason, return -1. Thus, the parent process cannot return from a call to exec until it knows whether the child process successfully loaded its executable. You must use appropriate synchronization to ensure this.
Note
Keep in mind
execis different from Unixexec. It can be thought of as a Unixfork+ Unixexec.
Tip: Access User Memory Space
execis the first syscall where a user passes a pointer to the kernel. Be careful and check if the pointer is valid. You may look up the page table to see if the pointer lays in a valid virtual memory region. Also, do make sure that each character within a string has a valid address. Don't just check the first address.With any invalid arguments, it's just fine to return -1. As for other syscalls with pointer arguments, please always check the validity of their memory addresses.
wait
int wait(int pid);
Waits for a child process pid and retrieves the child’s exit status. If pid is still alive, waits until it terminates. Then, returns the status that pid passed to exit. If pid did not call exit but was terminated by the kernel (e.g. killed due to an exception), wait must return -1. It is perfectly legal for a parent process to wait for child processes that have already terminated by the time the parent calls wait, but the kernel must still allow the parent to retrieve its child’s exit status, or learn that the child was terminated by the kernel.
wait must fail and return -1 immediately if any of the following conditions are true:
-
pid does not refer to a direct child of the calling process. pid is a direct child of the calling process if and only if the calling process received pid as a return value from a successful call to exec. Note that children are not inherited: if A spawns child B and B spawns child process C, then A cannot wait for C, even if B is dead. A call to wait(C) by process A must fail. Similarly, orphaned processes are not assigned to a new parent if their parent process exits before they do.
-
The process that calls wait has already called wait on pid. That is, a process may wait for any given child at most once.
Processes may spawn any number of children, wait for them in any order, and may even exit without having waited for some or all of their children. Your design should consider all the ways in which waits can occur. All of a process’s resources, including its struct thread, must be freed whether its parent ever waits for it or not, and regardless of whether the child exits before or after its parent.
Tip
Implementing wait requires considerably more work than the other syscalls. Schedule your work wisely.
File Operation Syscalls
In addition to process control syscalls, you will also implement the following file operation syscalls,
including open, read, write, remove, seek, tell, fstat, close. A lot of syscalls, right? Don't worry. It's not hard at all to implement them, as the skeleton code has a basic thread-safe file system already. Your implementations will simply call the appropriate functions in the file system library.
open
int open(const char* pathname, int flags);
Opens the file located at pathname. If the specified file does not exist, it may optionally (if O_CREATE is specified in flags) be created by open. Returns a non-negative integer handle called a file descriptor (fd), or -1 if the file could not be opened.
The argument flags must include one of the following access modes: O_RDONLY, O_WRONLY, or O_RDWR. These request opening the file read-only, write-only, or read/write, respectively.
File descriptors numbered 0 and 1 are reserved for the console: 0 is standard input and 1 is standard output. open should never return either of these file descriptors, which are valid as system call arguments only as explicitly described below.
Each process has an independent set of file descriptors. File descriptors in TacOS are not inherited by child processes.
When a single file is opened more than once, whether by a single process or different processes, each open returns a new file descriptor. Different file descriptors for a single file are closed independently in separate calls to close and they do not share a file position.
read
int read(int fd, void* buffer, unsigned size);
Reads size bytes from the file open as fd into buffer. Returns the number of bytes actually read (0 at end of file), or -1 if the file could not be read (due to a condition other than end of file, such as fd is invalid). File descriptor 0 reads from the keyboard.
write
int write(int fd, const void* buffer, unsigned size);
Writes size bytes from buffer to the open file with file descriptor fd. Returns the number of bytes actually written. Returns -1 if fd does not correspond to an entry in the file descriptor table. Writing past end-of-file would normally extend the file, and file growth is implemented by the basic file system.
File descriptor 1 and 2 should write to the console. You can simply use the kprint macro which also applys a lock on Stdout for you, making sure that output by different processes won't be interleaved on the console.
Tip
Before you implement syscall
writefor fd 1, many test cases won't work properly.
remove
int remove(const char* pathname);
Deletes the file at pathname. Returns 0 if successful, -1 otherwise. A file may be removed regardless of whether it is open or closed, and removing an open file does not close it.
What happens when an open file is removed?
You should implement the standard Unix semantics for files. That is, when a file is removed any process which has a file descriptor for that file may continue to use that descriptor. This means that they can read and write from the file. The file will not have a name, and no other processes will be able to open it, but it will continue to exist until all file descriptors referring to the file are closed or the machine shuts down.
seek
void seek(int fd, unsigned position);
Changes the next byte to be read or written in open file fd to position, expressed in bytes from the beginning of the file (0 is the file’s start). If fd does not correspond to an entry in the file descriptor table, this function should do nothing.
A seek past the current end of a file is not an error. A later read obtains 0 bytes, indicating end of file. A later write extends the file, filling any unwritten gap with zeros. These semantics are implemented in the file system and do not require any special effort in the syscall implementation.
tell
int tell(int fd)
Returns the position of the next byte to be read or written in open file fd, expressed in bytes from the beginning of the file. If the operation is unsuccessful, it returns -1.
fstat
// user/lib/fstat.h
typedef struct {
uint64 ino; // Inode number
uint64 size; // Size of file in bytes
} stat;
int fstat(int fd, stat* buf);
Fills the buf with the statistic of the open file fd. Returns -1 if fd does not correspond to an entry in the file descriptor table.
close
int close (int fd);
Closes file descriptor fd. Exiting or terminating a process must implicitly close all its open file descriptors, as if by calling this function for each one. If the operation is unsuccessful, it returns -1.
Testing
Here are all the tests you need to pass to get a full score in lab2:
- args-none
- args-many
- open-create
- open-rdwr
- open-trunc
- open-many
- read-zero
- read-normal
- write-zero
- write-normal
- close-normal
- exec-once
- exec-multiple
- exec-arg
- wait-simple
- wait-twice
- exit
- halt
- rox-simple
- rox-child
- rox-multichild
- close-stdio
- close-badfd
- close-twice
- read-badfd
- read-stdout
- write-badfd
- write-stdin
- boundary-normal
- boundary-bad
- open-invalid
- sc-bad-sp
- sc-bad-args
- exec-invalid
- wait-badpid
- wait-killed
- bad-load
- bad-store
- bad-jump
- bad-load2
- bad-store2
- bad-jump2
These test cases are recorded in tool/bookmarks/lab2.toml, and you can test the whole lab by
# under tool/
cargo tt -b lab2
To check the expected grade of your current codes, use
# under tool/
cargo grade -b lab2
Virtual Memory
Deadline & Submission
Code Due: Thursday 06/11 11:59pm
- Use
make submissionto tarball and compress your code assubmission.tar.bz2- Change the name of submission.tar.bz2 to
submission_yourStudentID.tar.bz2, e.g.,submission_20000xxxxx.tar.bz2- Submit this file to the
T-Lab3: Virtual Memoryon PKU course websiteDesign Doc Due: Sunday 06/14 11:59pm
- Submit your design document as a PDF to the
T-Lab3: Design Docon PKU course website
By now you have already touched almost every modules in Tacos. Tacos's thread module supports multiple threads of execution, and a thread could potentially be a process and execute any user programs. Syscalls, as the interface between user and OS, allow user programs to perform I/O or wait for other workers. However, it cannot fully utilize the machine -- for example, the user stack size is limited to 4KiB.
In this assignment, you will extend Tacos's virtual memory module. This assignment is extremely challenging, you will spend tons of time dealing with complex concurrency problems. You will extend the functionality of mem/ module, but you also need to modify things under other subdirectories, such as the page fault handler, to support your design.
You are required to start your lab3 implementation from a working lab2 implementation. To get a full score, you will need to pass all the tests in lab2 and lab3. See the testing page for details.
Tasks
Design Document
Download the design document template of project 3. Read through questions in the document for motivations, and fill it in afterwards.
Stack Growth
Hint
Following tasks are closely related to each other. You probably want to read through following tasks before designing and coding. A smart design could address multiple tasks at once.
Currently, a user stack is a single page at the top of the user virtual address space, and programs were limited to that much stack. It is your task to enable stack to grow its current size.
The first stack page need not be allocated lazily. You can allocate and initialize it with the command line arguments at load time, with no need to wait for it to be faulted in. But the following stack page need to be allocated lazily -- they shouldn't be allocated until a pagefault happens.
You should impose some absolute limit on stack size, as do most OSes. Some OSes make the limit user-adjustable, e.g. with the ulimit command on many Unix systems. On many GNU/Linux systems, the default limit is 8 MB.
Hint: Extract user program's stack pointer
To extend the stack lazily, you should devise a heuristic that attempts to distinguish stack accesses from other accesses.
spshould point to the lowest currently allocated byte. You need to obtain the compare the current value of the user program's stack pointer and the fault address. Within a system call or a page fault generated by a user program, you can retrievespfrom theFramestruct, which records the values of general purpose registers when the trap happens. Read through thetrap_entry_ufunction to see where the user's stack pointer is recorded when a user trap happens.
Note: Managing user program's memory with
UserPool
- As you may have noticed, the first stack page are allocated from
UserPool.UserPoolis a part of physical memory designed to be used by user programs. Each page in the data/code segment of a user program should comes fromUserPool.UserPool::dealloc_pagesis used to free a page inUserPool. Callingkfreeto free a page allocated fromUserPoolwill cause undefined behavior inUserPoolandkalloc.- Currently, when a user program exits, it automatically frees every page allocated from
UserPool. This is implemented inPageTable::destroy, where we callUserPool::dealloc_pagesfor every leaf, non-global page. (In Sv39 virtual memory schemes, global mappings exist in all address spaces (ref: RISC-V ISA Vol.2: Privileged Architecture). Tacos kernel exists in all address spaces, we use global maps to avoid flushing them in TLB in context switching. User pages should do not exist in all address spaces and we do not global maps it. Therefore, leaf and non-global implies user page mapping.)- Eanbling stack growth, as well as other functionality in this lab, requires you to allocate more pages for user programs. Make sure to allocate from
UserPool, and find proper way to manage them! Valid implementations may modifyUserPool, or have another data structure to manage the pages inUserPool.
Note: Page table management
- Stack growth may require you to modify current program's page table. Some interfaces in
src/mem/pagetable.rsmay be very helpful.- Following tasks may require you to frequently modify page tables to map/unmap virtual address to physical address. Some additional interfaces is needed!
- You should be very careful when you are modifying an active page table. You probably need to use fence to synchronize your change. You could use inline assembly to execute
fenceinstruction, or re-activate the page table using the interface insrc/mem/pagetable.rs.
Memory Map Syscalls
The file system is most commonly accessed with read and write system calls. A secondary interface is to "map" the file into virtual pages, using the mmap system call. The program can then use memory instructions directly on the file data. Following example uses mmap and munmap to print a file to the console:
#include "user.h"
void main (int argc, char *argv[])
{
void *data = (void *) 0x10000000; /* Address at which to map. */
int fd = open (argv[1]); /* Open file. */
mapid_t map = mmap (fd, data); /* Map file. */
stat s; fstat(fd, &s); /* Read file size */
write (1, data, s.size); /* Write file to console. */
munmap (map); /* Unmap file (optional). */
}
Detailed syscall's functionality as described below.
mmap
mapid_t mmap (int fd, void *addr);
Mmap maps the file open as fd into the process's virtual address space. The entire file is mapped into consecutive virtual pages starting at addr.
If successful, this function returns a "mapping ID" that uniquely identifies the mapping within the process.
A call to mmap may fail in four cases. First, it should fail if the file open as fd has a length of zero bytes. Second, it must fail if addr is not page-aligned or if the range of pages mapped overlaps any existing set of mapped pages, including the stack or pages mapped at executable load time. Third, it must fail if addr is 0, because 0 is used to represent null pointers. Finally, file descriptors 0, 1 and 2, representing console input and output, are not mappable. On failure, it must return -1, which should not be a valid mapping id.
If the file's length is not a multiple of PGSIZE, then some bytes in the final mapped page "stick out" beyond the end of the file. Set these bytes to zero when the page is faulted in from the file system, and discard them when the page is written back to disk.
Your VM system must lazily load pages in mmap regions and use the mmaped file itself as backing store for the mapping. That is, evicting a page mapped by mmap writes it back to the file it was mapped from.
munmap
void munmap (mapid_t mapping);
munmap unmaps the mapping designated by mapping, which must be a mapping ID returned by a previous call to mmap by the same process that has not yet been unmapped. All mappings are implicitly unmapped when a process exits, whether via exit or by any other means.
When a mapping is unmapped, whether implicitly or explicitly, all pages written to by the process are written back to the file, and pages not written must not be. The pages are then removed from the process's list of virtual pages.
Closing or removing a file does not unmap any of its mappings. Once created, a mapping is valid until munmap is called or the process exits, following the Unix convention.
If two or more processes map the same file, there is no requirement that they see consistent data.
Note
Unix handles consistent by making the two mappings share the same physical page, but the mmap system call also has an argument allowing the client to specify whether the page is shared or private (i.e. copy-on-write).
Hint: Lazily load
mmapregionTo lazily load page in
mmapregions, you need a table of file mappings to track which files are mapped into which pages. This is necessary to properly handle page faults in the mapped regions.
Segments Loading
Originally, Tacos's loader eagerlly loads a executable file's content in the memory (see src/userproc/load.rs for more details). You need to modify the loader such that it lazily load all those pages. That is, a page is loaded only as the kernel intercepts page faults for them.
Hint: Lazily load segments
- To lazily load page segments, you should record metadata for each lazily-loaded page, which allows you to know what location to read its content from disk later.
- In particular, originally (without lazily segments loading) if a page's content comes from reading offset
Xof the executable file, you should still read the content from offsetXof the executable file during page fault handling.- Valid solution may need to modify
load.rs, to record the metadata in the loading process, instead of allocating the pages all at once.
Swapping
Currently, when the work set of user programs exceeds the capacity of the main memory, Tacos will panic due to out of memory. However, if we temporarily swap out some less frequent used pages to secondary memory, such as disk, Tacos can support larger work set.
Note
By default, Tacos's
UserPoolcontains 256 pages. (The value is defined insrc/mem/palloc.rs, namedUSER_POOL_LIMIT). You shouldn't change this value. When those 256 pages are in use, new come allocate request will panic the kernel. You must find a way to either modifyUserPool's implementation to avoid panic, or to prevent such requests.
To support swapping, a secondary memory is needed. A special file, named .glbswap, exists in the disk image. You should use it to expand physical memory. See the helper functions in src/disk/swap.rs. To manage the swap space, you need to record which regions in the swap space is free, which regions is in use, and design interfaces that allows other modules to allocate and free slots in the swap space.
Hint: Swap space manager
Implement the swap space manager to support those functionalities.
A swap may happen when a new user page is needed (e.g. when a page fault from user happens), and there is no more free pages in UserPool. Swap usually contains several steps:
- Choose a victim page: You should select a victim page based on a global page replacement algorithm. In this lab, we requires you to implement a approximate LRU algorithm, such as "second chance" or "clock" algorithm.
- Swap out the victim page: After a victim page is selected, you should decide the swap-out strategy. To avoid unnecessary I/Os, you should not write unmodified pages to the swap space, because they value can be read directly from the executable file. Those pages modified since load (e.g. as indicated by the "dirty bit") should be written to swap. Your swap space manager should be able to serve the allocate request, as well as necessary disk I/Os. Just as segments loading, where you record the lazily load pages, you need to record the pages that are in the swap space.
- Swap in the desired page: Desired pages may sit in executable files, or swap space. Use you recorded information to read them from disk.
Hint: Do not implement everything all at once
It is a complex task, you should implement it step by step. First implement a naive replacement policy, debug on it to make sure your swap out & swap in works well, and then move to the replacement policy.
Hint: Supplementary page table and frame table
- As you may have noticed, both the swapping task and the segments loading task require keeping track of relationship between virtual memory address and their actual store locations (in RAM, in swap space, or in executable files). The datastructure that records this relationship are called supplementary page table. Each user program should have a supplementary page table.
- To choose a victim page, you probably want to know some additional information about a physical page (e.g. is it a dirty page? is it accessed?). Such additional information could be recorded in a data structure called frame table (Here the frame refers to a physical page). Design a global frame table and implement your page replacement on it.
- Data structures provided by
alloccrate may be very helpful when implementing those tables and managers!
Access user memory
After enabling swapping and lazily loading, accessing memory become more challenging: user is likely to pass addresses that refer to such non-present pages to system calls! If kernel code accesses such non-present user pages, a page fault will result. This means when accessing user memory, your kernel must either be prepared to handle such page faults, or it must prevent them from occurring.
Hint: Access user memory
- To prevent such page faults from happening, you could extend your frame table to record when a page contained in a frame must not be evicted. (This is also referred to as "pinning" or "locking" the page in its frame.)
- To be able to handle such page faults, you must prevent page faults when it is holding resources it needs to handle these faults, such as locks. Otherwise deadlocks or other concurrent problems may happen.
Testing
To get a full score in lab3, you need to pass all the tests in lab2.toml and lab3.toml.
To run the tests in lab2, use
# under tool/
cargo tt -b lab2
To run the tests in lab3, use
# under tool/
cargo tt -b lab3
To get the expected score, run cargo grade -b lab2 and cargo grade -b lab3 together. Let A be the grade of cargo grade -b lab2, and B be the grade of cargo grade -b lab3, your final score in lab3 = 0.4 * A + 0.6 * B
Testing
For your convenience during the labs, we've provided a set of tools. They are in ./tool/ directory. In the rest of this section, we'll use ./tool/ as the directory of the tools, and ./ as the directory of the OS.
To use the tools you'll need to set your working directory under
./tool/but not./, because the rust toolchain used by the tools (i.e., x86) is different from that by the OS itself (i.e., RISC-V).
For the usage of the toolset, you can run this command under ./tool/ for help information:
cargo h
Such command is an alias of a more complicated command. For its original version (and other aliases) please refer to ./tool/.cargo/config.toml.
In the rest of this section, we'll introduce the functions of the toolset.
Build
Basically, you can build the OS manually by running cargo under ./. However, to correctly run and test your OS, there are some other building works, including building user programs and the disk image. Since these peripheral parts ar not written in Rust, building them manually is less convenient, and the building order makes the works more confusing.
In the toolset, we've provided a build tool. Run cargo h build for the usage (the alias of build tool is cargo bd):
Build the project
Usage: tool build [OPTIONS]
Options:
-c, --clean Clean
-r, --rebuild Clean and rebuild. `--clean` will be ignored
-v, --verbose Show the build process
-h, --help Print help information
You can simply build the whole project, including OS, user programs and disk image by cargo bd. Also, you can clean or rebuild the project by specifying the -c and -r arguments. By the -v you can see the output of the building process (though they might not be helpful, just for fun).
To manually build the OS, you can run cargo under ./. In this way you can control the features you want to include. Existing feathres are listed in ./Cargo.toml.
To manually build use programs, you can run make under ./. All of the user programs are written in C and located under ./user/. If you want to write your own user programs, you can add *.c files under ./user/userprogs/ or ./user/vm/. If you need to add a new sub-directory, like ./user/yours/, you'll need to add user/yours to the SRC_DIRS in ./user/utests.mk, otherwise your new program will not be added into disk image and your OS will not find it.
To manually build the disk image, uses make build/disk.img under ./.
We do not recommend you to use these two way (./tool/ & ./) simultaneously, for the grading process is based on ./tool/. In essential, we do not recommend you to change any of the config files (Cargo.toml, makefile and config.toml). If you need to change them, please contact the TA and clarify your special testing methods.
Test
The toolset also provides a tool to test your OS for the test cases that are included in the grading process. Run cargo h test for the usage (the alias of test tool is cargo tt):
Specify and run test cases
Usage: tool test [OPTIONS]
Options:
-c, --cases <CASES>
The test cases to run. Only the name of test case is required.
Example: `tool test -c args-none` , `tool test -c args-none,args-many`
-b, --books <BOOKS>
Load specified bookmarks and add to the test suite
-p, --previous-failed
Add test cases that failed in previous run to the test suite
--dry
Only show the command line to run, without starting it
--gdb
Run in gdb mode. Only receive single test case
-g, --grade
Grading after test
-v, --verbose
Verbose mode without testing. Suppress `--gdb` and `--grade`
-h, --help
Print help information (use `-h` for a summary)
The test tool has several ways to use.
The first way is to test one or a few specified cases. The usage is cargo tt -c <args>. An example is cargo tt -c args-none,args-many, which specifies the args-none and args-many cases. Some test cases need to pass special arguments to the OS through QEMU (like args-many), but you'll not need to pass it manulally. The test tool takes over it.
The first way is not convenient when your are testing too many cases. The second way, specified by -b, is introduced to solve this problem. In this way, the tool receive a set of toml files which specify the test cases and the arguments, then run them in one shot. For example, if you want to test the entire lab1 and lab2, you can run cargo tt -b lab1,lab2. The specified toml files are called "bookmarks". They must locate in ./tool/bookmarks/. We've provided four of them with the code base: lab1, lab2, lab3 and unit. You cannot change these files, but you can create your own bookmarks.
The third way allows you to test the cases that you've just failed. Whenever the test tool run, it records the failed test cases in a bookmark called previous-failed.toml. To only test these cases in your next run, you can use this bookmark. We've also provided an argument, -p, as an alias.
The fourth way is the grading mode. You can use the -g, --grade addon argument, or use the alias cargo grade. This is similar to test mode (ways 1-3), except the tool will show the grade of your OS when the test ends. We also uses this way to grade your submission.
The fifth way is the gdb mode, specified by an addon argument --gdb (example: cargo tt -c args-none --gdb). An alias is also provided: cargo gdb. In this way, the test tool will start a background gdb process, which you can attach to via another gdb client. This is to help you to debug your OS in gdb without writing confusing QEMU cmds. Please note that in this mode, only one test case can be passed to the test tool. Bookmarks or more than one cases will be rejected.
The sixth way is dry run mode, specified by --dry, which is an addon argument. In the dry run mode, the test tool will not really start your OS, but show the commands for each test cases. These commands can be used under ./. For example, if we run cargo tt -c args-many --dry, the outpout will be:
# Command for args-many:
cargo run -r -q -F test-user -- -append "args-many a b c d e f g h i j k l m n o p q r s t u v"
You can use the shown command under ./ to test the args-many case. In this way, you can see the entire log info of your OS. In default way, the test tool will only report the last 10 lines. You can also use -v for the entire output, however, the grading will not function under verbose mode.
Bookmark
In the test section, we said that the test tool can receive a bookmark in ./tool/bookmarks/, and you can build your own bookmarks for convenience. The bookmark tool is provided to let you build your bookmarks. Run cargo h book to see the usage (the alias of bookmark tool is cargo bk):
Remember specific test cases
Usage: tool book [OPTIONS] --name <NAME>
Options:
-n, --name <NAME>
The name of the bookmark.
Bookmark will be saved in `/bookmarks/<name>.json`
-d, --del
Delete mode. Turn 'add' into 'delete' in other options.
If no test cases are specified, delete the whole bookmark (with its file!).
-c, --cases <CASES>
Test cases to add in this bookmark
-b, --books <BOOKS>
Bookmarks to load and add to this bookmark
-p, --previous-failed
Add test cases that failed in previous run to the bookmark
-h, --help
Print help information (use `-h` for a summary)
In essential, the bookmarks record the name, arguments and grade of each test case. Some of the arguments are complex, and the grade is not that important for creating bookmarks. So the bookmark tool is to provide a way that only creates bookmarks by the name.
An example usage, which create a bookmark named mybk.toml and including args-none, args-many test cases are:
cargo bk -n mybk -c args-none,args-many
The usage and meaning of bookmark tool is quite similar to the test tool. The -c is used to add specified cases. The -b is used to add all the cases in another bookmark (example: cargo bk -n mylab2 -b lab2). The -p is used to add the failed test cases in your last run (example: cargo bk -n failed-in-run-87 -p).
The tool also provide -d for delete mode. For example, if the args-none is ensured to be passable, and you do not care about it anymore, you can delete it from mybk by running cargo bk -n mybk -d -c args-none. This mode can also receive -b and -p. You may want to keep a backup of your important bookmarks when using this mode!
Remote test server
Some bugs may perform differently on TA's testing environment. So we add a a remote test server, so that you can submit and check your score in TA's testing environment. You can check the test script to see how to use the remote test server. And please modify the SERVER_URL in client.py with the url provided by TA.
If you want to know how the server works, please check this repo.
Debugging
The most useful debug tool must be directly print some messages to the console. kprintln is the kernel version of println, you can call it from almost anywhere in the kernel. kprintln is not just more than just examining data. It can also help figure out when and where something goes wrong, even when the kernel crashes or panics without a useful error message. You could thus narrow the problem down to a smaller amount of code, and even to a single instruction.
As you may have noticed, the debug cargo feature enables a lot of debug messages printed by kprintln. To run the empty example with debug feature, use following command in the project root directory:
cargo run -F debug
When you are debugging some test cases, running it with debug feature may (or may not) be helpful. You could use the testing tool in the tool/ directory to find the testing command:
Workspace/tool/> cargo tt -c args-none --dry
Command for args-none:
cargo run -r -q -F test-user -- -append args-none
And then run it with debug feature (without the -r and -q option):
Workspace/tool/> cd ..
Workspace/> cargo -F test-user,debug -- -append args-none
Assert
Assertions are also helpful for debugging, because they can catch problems early, before they'd otherwise be noticed. You could add assertions throughout the execution path where you suspect things are likely to go wrong. They are especially useful for checking loop invariants. They will invoke the panic! macro if the provided expression cannot be evaluated to true at runtime.
Following assertions may be helpful for your developent: assert!, assert_eq!, assert_matches!, ...
Our tests also use assertions to check your implementations.
GDB
You can run Tacos under the supervision of the GDB debugger.
- First, you should start Tacos, and freeze CPU at startup, and open a remote gdb port to wait for connection. You could enable it by passing
-Sand-soption to qemu. For the empty example's execution, you could run following command in the project root directory:
/Workspace/> cargo run -- -s -S
For a particular test case, you could use the tool introduced in the test section, in tool/ directory. For example, to debug the args-none testcase, you could start Tacos by:
/Workspace/tool> cargo gdb -c args-none
Use 'gdb-multiarch' to debug.
This may take some time, so please be patient.
- The next step is to use gdb to connect the guest kernel:
> gdb-multiarch
# In gdb, we've provided helpful tools.
# See ./.gdbinit for details.
# Load symbols of debug target.
(gdb) file-debug
# Get into qemu.
(gdb) debug-qemu
# Set breakpoints...
(gdb) b ...
# Start debugging!
(gdb) continue
FYI, file-debug and debug-qemu are gdb macros defined in .gdbinit file.